12장. 커서
커서는 테이블에서 여러 개의 행을 쿼리한 후에, 쿼리의 결과인 행 집합을 한 행씩 처리하기 위한 방식이다.
행의 집합을 다루는 데 제공해주는 편리한 기능이며, SQL Server의 성능을 느리게 하는 요인이 될 수 있으므로, 특별한 경우가 아니라면 되도록 사용하지 않을 것을 권장한다. 커서는 파일처리시의 파일 포인터와 비슷한 작동을 한다.

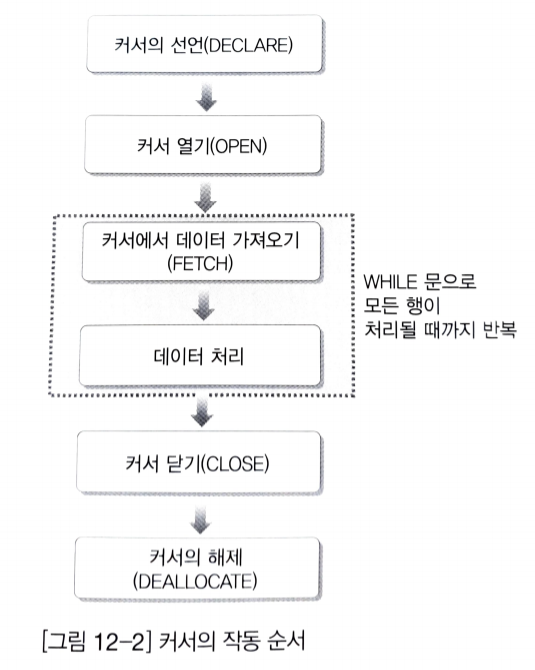
위 파일이 있다고 가정해보자. 이 파일을 처리하는 순서는 다음과 같다.
1. 파일을 연다(open), 그러면 파일 포인터는 파일의 제일 시작(BOF : Begin Of File_을 가리키게 된다.
2. 처음 데이터를 읽는다. 그러면 '이승기'의 데이터가 읽어지고, 파일 포인터는 '김범수'로 이동한다.
3. 파일의 끝(EOF : End Of File)까지 반복한다.
3-1. 읽은 데이터를 처리한다.
3-2. 현재 파일포인터가 가리키는 데이터를 읽는다. 파일포인터는 자동으로 다음으로 이동한다.
4. 파일을 닫는다.(Close)
커서의 작동 순서
커서를 이용해서 고객의 평균 키를 구해보자
use sqlDB
DECLARE userTbl_cursor CurSOR GLOBAL
FOR SELECT height FROM userTBL; -- 이 커서는 userTBL에서 height의 행 집합을 가져오는 커서다.
OPEN userTbl_cursor
-- 우선, 사용할 변수를 선언한다.
DECLARE @height INT -- 고객의 키
DECLARE @cnt INT = 0 -- 고객의 인원수(=읽은 행의 수)
DECLARE @totalHeight INT = 0 -- 키의 합계
FETCH NEXT FROM userTbl_cursor INTO @height -- 첫 행을 읽어서 @height 변수에 넣는다.
--성공적으로 읽어졌다면 @@FETCH_STATUS 함수는 0을 반환하므로, 계속 처리한다.
-- 즉, 더 이상 읽은 행이 없다면 (=EOF을 만나면) WHILE 문을 종료한다.
WHILE @@FETCH_STATUS = 0
BEGIN
SET @cnt += 1 -- 읽은 개수를 증가시킨다.
SET @totalHeight += @height -- 키를 계속 누적시킨다.
FETCH NEXT FROM userTbl_cursor INTO @height -- 다음 행을 읽는다.
END
-- 고객 키의 평균을 출력한다.
PRINT '고객 키의 평균 ==> ' + CAST(@totalHeight/@cnt AS CHAR(10))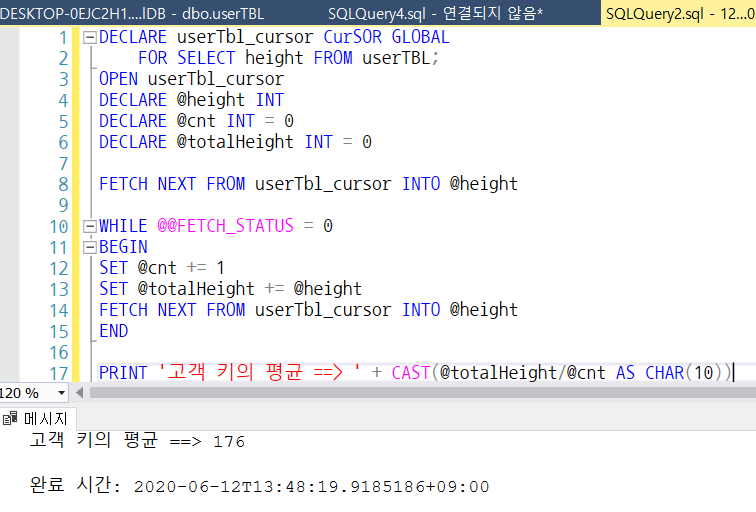
위의 예제를 실행한 후에, 커서를 닫고 할당을 해제까지하면 사용이 완료된다.
CLOSE userTbl_cursor; -- 커서를 닫는다
DEALLOCATE userTbl_cursor; -- 커서의 할당을 해제한다
커서의 선언
커서가 어떻게 사용될 것이고, 또 어떠한 성격을 가지는지의 여부가 커서의 선언부분에서 모두 결정된다.
ISO 표준 문법
DECLARE cursor_name [ INSENSTIVE ] [ SCROLL ] CURSOR
FOR select_statement
[ FOR { READ ONLY | UPDATE [ OF column_name [ , . . . n] ] } ]위의 평균 키를 구한 예제에서 봤듯이 userTbl을 처리하는 커서는 다음과 같이 정의한다.
DECLARE userTbl_cursor CURSOR GLOBAL
FOR SELECT height FROM userTbl;
[ LOCAL | GLOBAL ]
GLOBAL은 전역 커서를, LOCAL은 지역 커서를 지정한다.
전역 커서는 모든 저장 프로시저나 일괄 처리에서 커서의 이름을 참조할 수 있고, 지역 커서는 지정된 범위(Scope)에서만 유효하며 해당 범위를 벗어나면 자동으로 소멸한다. 예를들어 저장 프로시저 안에서 지역 커서를 사용 시에는 저장 프로시저가 끝나는 시점에 커서도 소멸한다. 하지만, OUTPUT 매개변수로 저장 프로시저의 외부로 커서를 돌려주면 그 커서를 참조하는 변수가 해제되거나 소멸할 때 커서도 같이 소멸된다.
커서 닫기
커서 닫기 형식은 다음과 같다.
CLOSE userTbl_cursor;지역 커서의 경우에는 범위를 빠져나가게 되면, 자동으로 커서가 닫히게 된다.
즉, 저장 프로시저나 트리거에서 커서를 사용하다가 종료되면 커서도 닫히게 되므로, CLOSE문을 써주지 않아도 된다.
커서 할당 해제
커서 할당 해제 형식은 다음과 같다.
DEALLOCATE userTbl_cursor;CLOSE와 같이 지역 커서의 경우에는 범위를 벗어나면 자동으로 할당도 해제된다.
커서의 활용
커서와 일반 쿼리의 성능을 비교해보자
커서를 이용해서 고객의 평균 키를 구하는 예제)
DECLARE @index INT = 0, @bYear INT = 0, @age INT = 0 -- 변수 선언
SET @index = 0
DECLARE cur CURSOR FOR
SELECT birthYear FROM userTBL; -- 반복문을 돌릴 테이블 지정
OPEN cur;
FETCH NEXT FROM cur INTO @bYear; -- 패치할때마다 bYear에 하나씩 넣어줌
WHILE @@FETCH_STATUS = 0 --FFTCH STATUS가 0이 될때까지 돈다
BEGIN
SET @age += (YEAR(GETDATE()) - @bYear) + 1
SET @index += 1; -- 커서가 넘어갈때마다 회원수 카운팅
FETCH NEXT FROM cur INTO @bYear;
END
CLOSE cur -- 커서 닫기(자주씀)
DEALLOCATE cur -- 커서 할당 해제(잘안씀)
PRINT '나이합은 ' + CAST(@age AS VARCHAR) -- INT형 데이터를 문자열로 형변환해서 PRINT로 출력
PRINT '회원수는 ' + CAST(@index AS VARCHAR)
PRINT '회원들의 평균 나이는 ' + CAST((@age / @index) AS VARCHAR(5))
13장. 트리거
8장에서 데이터의 무결성을 위한 제약조건(기본키, 외래키 등)을 공부했다. 트리거는 제약조건과 더불어서 데이터의 무결성을 위한 또 다른 기능이다. 종류로는 DML트리거, DDL트리거, LOGON트리거 세 가지가 있고, 테이블 또는 뷰에 부착(Attach)되는 프로그램 코드이다. 저장 프로시저와 비슷하게 작동하지만 직접 실행시킬 수는 없고 오직 해당 테이블이나 뷰에 이벤트(입력, 수정, 삭제)가 발생할 경우에만 실행된다. 또, 저장프로시저와 달리 매개변수나 리턴값을 사용할 수 없다.
(트리거는 사전적 의미로 '방아쇠'를 뜻하며, 방아쇠를 당기면 '자동'으로 총알이 나가듯이, 트리거는 테이블에 무슨 일이 일어나면 '자동'으로 실행된다.)
CREATE TRIGGER testTrg -- 트리거 이름
On testTbl -- 트리거를 부착할 테이블
AFTER DELETE, UPDATE -- 삭제, 수정 후에 작동하도록 지정
AS
PRINT'(트리거가 작동했습니다'); -- 트리거 실행시 작동되는 코드들
간단한 트리거를 생성하고 결과를 확인해보자.
트리거의 종류
AFTER 트리거
테이블에 INSERT, UPDATE, DELETE등의 작업이 일어났을때 작동, 해당 작업 후에 작동함
테이블에만 작동하며 뷰에는 작동하지 않음
INSETAD OF 트리거
AFTER 트리거는 테이블에 이벤트가 작동한 후에 실행되지만, INSTEAD OF 트리거는 이벤트가 발생하기 전에 작동하는 트리거다. 테이블뿐 아니라 뷰에도 작동되며, 주로 뷰에 업데이트가 가능하도록 할때 사용된다.
AFTER 트리거와 마찬가지로 INSERT, UPDATE, DELETE 세 가지 이벤트로 작동한다.
CLR 트리거
T-SQL 저장 프로시저 대신, 닷넷 프레임워크에서 생성되는 트리거를 말한다.
트리거의 사용
트리거를 한번 사용해보자. 우선, 테이블을 하나 생성해보자


CREATE OR ALTER TRIGGER trg_BackupUserTBL
ON userTbl
AFTER UPDATE, DELETE -- 삭제 또는 수정
AS
BEGIN
DECLARE @trgType NVARCHAR(3) -- 트리거타입
IF (COLUMNS_UPDATED() > 0 ) -- 업데이트 되었다.
BEGIN
SET @trgType = '수정'; -- 데이터를 수정하면 백업테이블에 '수정'이 저장
END
ELSE -- 삭제
BEGIN
SET @trgType = '삭제'; -- 데이터를 삭제하면 백업테이블에 '삭제'가 저장
END
INSERT INTO backup_userTBL
SELECT userID, name, birthYear, addr, mobile1,
mobile2, height, mDate, @trgType
FROM deleted; -- 값이 수정되고 원래 데이터가 들어간 임시테이블
END
GO

UPDATE문에 적용
위에서 테이블을 생성했다면 새 쿼리창에서 아래의 코드를 작성해보자

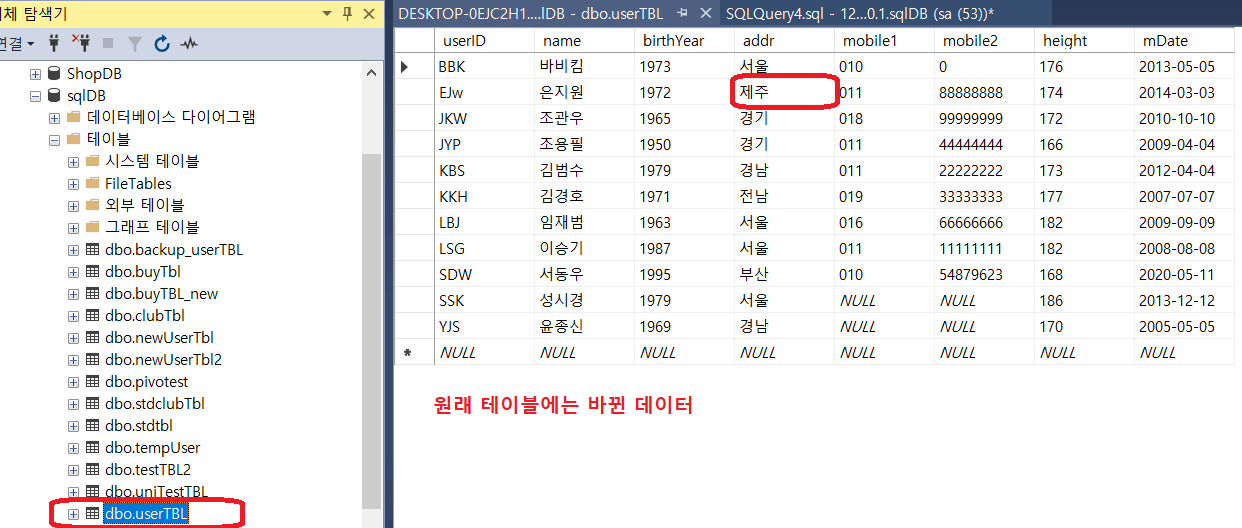

위의 이미지처럼 원래 테이블의 은지원의 주소가 경북 -> 제주로 바뀌면서 트리거테이블(백업테이블)에는 원래 주소인 경북이 저장되었다.
DELETE문에도 적용해보자
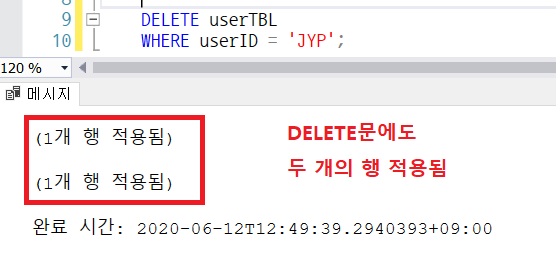


위의 새 쿼리창에 DELETE문이 적용되지 않았을때가 있는데, userTbl이 buyTbl과 관계가 맺어져있을때 오류가 뜰 수 있다. 그럴때는 buyTbl에서 외래 키 관계를 띄운다음 INSERT 및 UPDATE 사양을 계단식 배열로 바꿔주면 오류가 사라진다.

- 예제와 같은 경우를 생각해보자. 누군가 A라는 테이블에 행을 실수로 삭제한다면, 삭제된 행의 내용을 복구하는 것도 어렵고, 누가 지웠는지 추적하는 것도 쉬운 일이 아니다. 이러한 경우에 A 테이블에서 행이 삭제되는 순간에 B라는 테이블에 A 테이블에서 삭제된 행의 내용, 시간, 삭제한 사용자를 기록해 놓는다면 이러한 문제점을 해결할 수 있을 것이다.
- 참고로 트리거는 저장 프로시저와 달리 특별히 실행시키지 않아도 자동으로 실행되므로, 더 편리하게 사용될 수 있으나 시스템의 성능을 저하시키는 요인이 되기도 하므로 꼭 필요한 곳에만 사용해야 한다.
트리거의 사용
트리거가 생성하는 임시테이블
inserted 테이블
- INSERT와 UPDATE 작업 시에 변경 후의 행 데이터와 동일한 데이터가 저장된다.
deleted 테이블
- DELETE와 UPDATE 작업이 수행되면 우성 해당 테이블에 삭제 또는 변경된 후에, 삭제 또는 변경되기 전의 데이터가 저장된다.
INSTEAD OF 트리거 (BEFORE 트리거)
테이블에 변경이 가해지기 전에 작동되는 트리거
주로 뷰에 행이 삽입되거나 변경, 삭제 될때 사용된다.
INSTEAD OF 트리거가 작동하면, 시도된 INSERT, UPDATE, DELETE 문은 무시됨.
기타 트리거에 관한 사항
다중 트리거
하나의 테이블에 동일한 트리거가 여러 개 부착되어 있는 것을 말한다. 예로, AFTER INSERT 트리거가 한 개 테이블에 2개 이상 부착되어 있을 수도 있다.
중첩 트리거
트리거가 또 다른 트리거를 작동시키는것을 말한다.

1. 고객이 물건을 구매하게 되면, 물건을 구매한 기록이 '구매 테이블'에 (1)INSERT 된다.
2. '구매 테이블'에 부착된 INSERT 트리거가 작동한다. 내용은 '물품 테이블'의 남은 개수를 구매한 개수만큼 빼는 (2)UPDATE를 한다.
(쿠팡에서 물건사면 즉시 남은 수량이 하나 줄어드는 것을 생각하면 쉽다)
3. '물품 테이블'에 장착된 UPDATE 트리거가 작동한다. 내용은 '배송 테이블'에 배송할 내용을 (3)INSERT하는 것이다.
위의 이미지에서 하나의 '물건 구매(INSERT)' 작업으로 2개의 트리거가 연속적으로 작동한 것을 확인할 수 있다. 이를 중첩 트리거라고한다.
14장을 시작하기 전에 밑의 파일을 다운받아서 쿼리창에 실행해보자.





2줄 요약
1. 파일을 다운받아서 새 쿼리창에 다운받은 파일을 연다.
2. 4줄 ~ 9줄 따로 실행, 12줄 ~ 141줄 따로 실행, 144줄 ~ 204줄을 따로 실행해준다.
14장. 전체 텍스트 검색
풀텍스트 검색 서비스(Full text Search Service)는 SQL Server 추가 기능이다.
간단하게 정의하면 긴 문장으로 구성된 열의 내용을 검색할 때 전체 텍스트 인덱스를 사용해서 빠른 시간을 검색하는 것이라고 볼 수 있다. 기존 인덱스가 중간에 들어있는 글자로 검색할 때는 인덱스를 사용하지 못하는 문제점을 해결해주며, 'SQL Full-text Filter Daemon Launcher'라는 서비스가 등록되고 가동되어야 한다.


전체 텍스트 인덱스
신문기사와 같이, 텍스트로 이루어진 문자열 데이터의 내용을 가지고 생성한 인덱스를 말한다. SQL Server에서 생성한 일반적인 인덱스와는 몇 가지 차이점이 있다.
- 전체 텍스트 인덱스는 테이블 당 하나만 생성할 수 있다.
- 전체 텍스트 인덱스는 데이터를 추가하는 채우기(Population)는 일정 예약이나 특별한 요청에 의해서 수행되거나, 새로운 데이터를 Insert할 때 자동으로 수행되게 할 수도 있다.
- 전체 텍스트 인덱스는 char, varchar, nchar, nvarchar, text, ntext, image, xml, varbinary(max), FILESTREAM 등의 열에 생성 가능하다.
- 전체 텍스트 인덱스를 생성할 테이블에는 기본키나 유니크키가 있어야 한다.
형식)

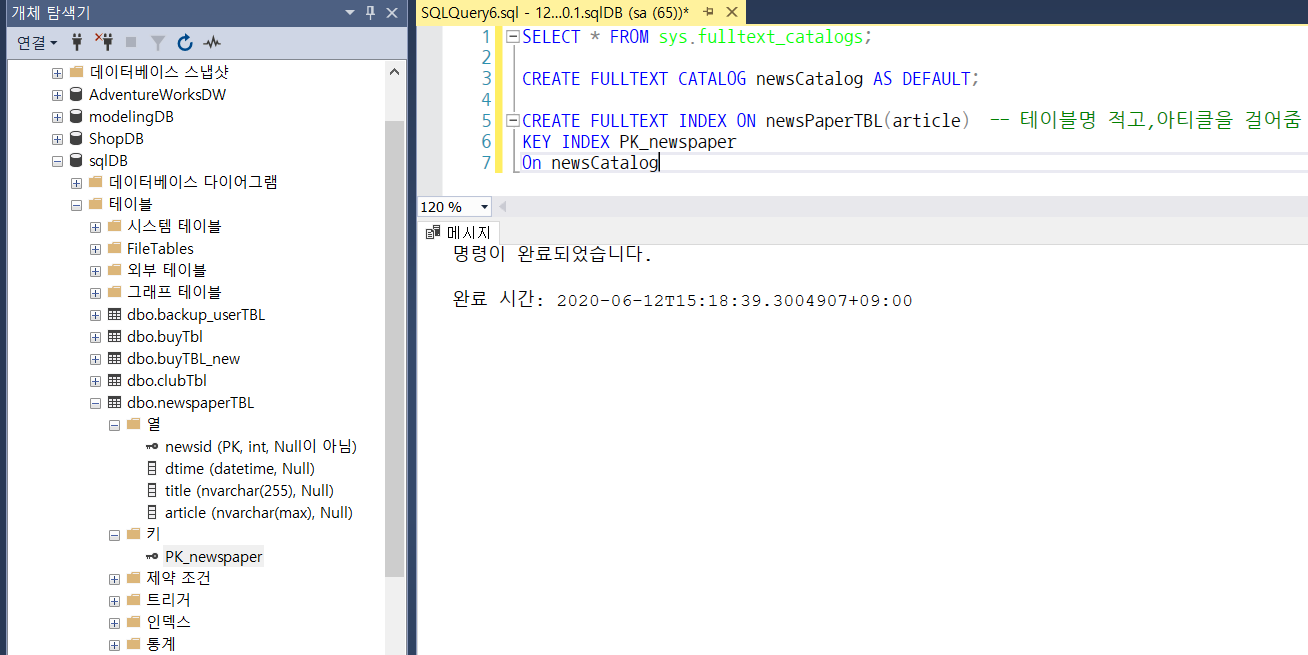
전체 텍스트 카탈로그
전체 텍스트 인덱스가 저장되는 가상의 공간이라고 생각하면 된다. 하나의 전체 텍스트 카탈로그에는 여러 개의 전체 텍스트 인덱스가 저장된다. 기억할 점은 전체 텍스트 인덱스가 생성되기 전에 생성해 놓아야 한다.
형식)

SQL Server 2008부터는 전체 텍스트 인덱스가 DB에 저장되기때문에 지금은 중요하지 않다.
전체 텍스트 인덱스 채우기
전체 텍스트 인덱스를 생성하고 관리하는 것을 말한다. 이 '채우기'의 방법에는 세 가지 종류가 있다.
전체 채우기
처음 전체 텍스트 인덱스를 생성할 때 지정한 열의 모든 데이터 행에 대해서 인덱스를 생성하는 것을 말한다. 일반적으로 처음에는 전체 채우기를 수행해야 한다.
변경 내용 추적 기반 채우기
전체 채우기를 수행한 이후에, 변경된 내용을 채우는 것을 말한다.
증분 타임스탬프 기반 채우기
증분 채우기는 마지막 채우기 후 추가, 삭제, 수정된 행에 대해서 전체 텍스트 인덱스를 업데이트한다. 이를 사용하려면 테이블에 타임스탬프 데이터 형식의 열이 있어야 하며, 만약 타임스탬프 열이 없는 테이블에 대해 증분 채우기를 하면 전체 채우기 작업이 수행되므로 성능에 부하가 생길 수 있다.
중지 단어 및 중지 목록
전체 텍스트 인덱스는 긴 문장에 대해서 인덱스를 생성하기 때문에 그 양이 커질 수 밖에 없다. 그러나 실제로 검색해서 무시할 만한 단어들은 아예 전체 텍스트 인덱스로 생성하지 않는 편이 좋다. 이를 '중지 단어'라고 부른다.

별 의미가 없는 1, 3, 6, 7번을 중지 단어로 지정하고 각 언어 별로 많이 사용되는 '중지 단어'들을 제공해준다.
중지 목록(stoplist)은 중지 단어들을 관리하기 위한 집합이다. 사용자는 중지 목록을 생성해서 그 중지 목록에 중지 단어를 추가하면 된다.
전체 텍스트 검색을 위한 쿼리
전체 텍스트 인덱스를 생성한 후에, 그것을 이용하는 쿼리는 일반 SELECT 문의 WHERE 절 또는 FROM 절에 관련된 키워드를 사용하면 된다.
CONTAINS
특정 단어 또는 구와 정확히 일치하거나 비슷하게 일치하는 단어를 검색하거나 서로 근접한 단어를 검색하거나 가중치 검색을 수행하는 구문이다. CONTAINS는 문자 기반 데이터 형식이 포함된 전체 텍스트 인덱싱된 열에서 SQL Server 전체 텍스트 검색을 수행하기 위해 Transact-SQL SELECT문의 WHERE절에 사용되는 조건자이다.


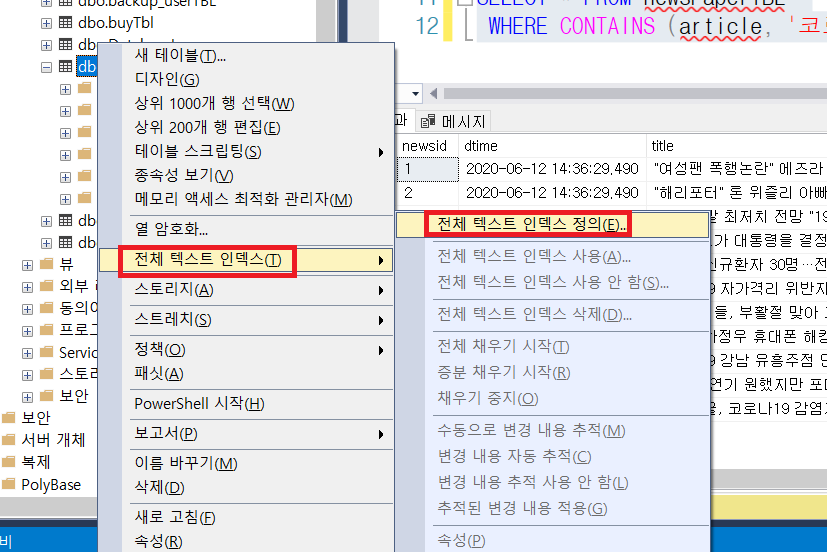



SELECT * FROM sys.dm_fts_index_keywords(DB_ID(),OBJECT_ID('dbo.FulltextTBL'));
SELECT * FROM FulltextTBL
WHERE CONTAINS (description, '남자');
'개발자과정준비 > 데이터베이스(DB)' 카테고리의 다른 글
| [DB] 5. 인덱스, 트랜잭션, 데이터베이스 모델링, 저장 프로시저, 사용자 정의 함수 (0) | 2020.06.12 |
|---|---|
| [DB] 4. JOIN, UNION, SQL프로그래밍, 테이블, 뷰 (0) | 2020.06.10 |
| [DB] 3. ROLLUP(), WITH절, INSERT문, 데이터형식의 종류, JSON 데이터, PIVOT (0) | 2020.06.09 |
| [DB] 2. 운영 실습, SELECT 문 (0) | 2020.06.08 |
| [DB] 1. DBMS 개요, DB 생성 실습 (0) | 2020.06.08 |
