SELECT문 계속
select userID, price, amount
FROm buyTBL;
-- 테이블을 작성했는데 통계를 내고싶다 select SUM(price * amount)
FROM buyTbl;
-- 누가 얼만큼 샀는지 알 수가없다select userID,
SUm(price * amount) AS '총 구매금액'
FROM buyTbl
-- WHERE userID = 'BBK' -- BBK인사람 검색가능
-- WHERE groupName = '전자' --전자제품산거만 출력
-- WHERE SUm(price * amount) >= 1000 -- 오류뜸, SUM같은 연산은 헤빙
GROUP BY userID
HAVING SUM(price * amount) >= 1000 -- SUM이 1000원 이상인사람 호출
ORDER BY SUM(price * amount) ASC;
-- 이 구문없으면 BBK, KBS순인데 역순으로 정렬해줌


ROLLUP() 함수
총합 또는 중간합계가 필요하다면 GROUP BY와 함께 ROLLUP() 또는 CUBE()를 사용하면 된다. 만약 분류(groupName)별로 합계 및 그 총합을 구하고싶으면 아래의 구문을 사용해보자.

중간중간에 num 열이 NULL로 되어 있는 추가된 행이 각 그룹(groupName)의 소합계를 의미한다. 또, 마지막 행은 총 합계를 의미한다.

AS는 열이름을 새겨준다
CUBE() 함수
CUBE() 함수도 ROLLUP()과 비슷한 개념이지만, CUBE()는 다차원 정보의 데이터를 요약하는데 더 적당하다.
근데 CUBE문은 많이 쓰질않고 보통 ROLLUP을 더 많이 쓴다.
with절과 CTE
WITH절은 CTE(Common Table Expression)을 표현하기위한 구문이다. CTE는 기존의 뷰, 파생 테이블, 임시 테이블 등으로 사용되던 것을 대신할 수 있으며 더 간결한 식으로 보여지는 장점이 있다.
CTE는 비재귀적(Non-Recusive) CTE와 재귀적(Recursive) CTE 두 가지가 있다.
비재귀적 CTE
비재귀적 CTE는 말 그대로 재귀적이지 않은 CTE이며 단순한 형태이다. 복잡한 쿼리 문장을 단순화시키는 데에 적합하게 사용될 수 있다.
WITH CTE_테이블이름(열이름)
AS
(
<쿼리문>
)
SELECT 열이름 FROM CTE_테이블이름;예제를 들기 위해 앞에했던 buyTbl 예제에서 총 구매액을 구하는 예시를 다시 살펴보자.

위의 결과를 총 구매액이 많은 사용자 순서로 정렬하고 싶으면 어떻게 해야할까? ORDER BY 문을 첨가해도되지만 그럴경우에는 SQL 문이 더욱 복잡해 보일 수 있다.

각 지역별로 가장 큰 키를 1명씩 뽑은 후에, 그 사람들 키의 평균을 내보는 예제를 써보자. 전체의 평균이라면 집계 함수AVG(height)만 사용하면 되지만, 각 지역별로 가장 큰 1명을 우선 뽑아야하므로 복잡해진다. 이럴때 CTE를 사용할 수 있다.

재귀적 CTE
자기자신을 반복으로 호출한다는 의미를 내포한다. 가장 많은 재귀적인 예는 회사의 부서장과 직원의 관계이다.
INSERT문
INSERT는 테이블에 데이터를 삽입하는 명령어이다. 기본적인 형식은 아래와 같다.
INSER [INTO] <테이블> [(열1, 열2, ...)] VALUES (값1, 값2 ... )
주의할점은 테이블 이름 다음에 나오는 열은 생략이 가능하다. 하지만, 생략할 경우에 VALUE 다음에 나오는 값들의 순서 및 개수가 테이블이 정의된 순서 및 개수와 동일해야 한다.
예시)
INSERT INTO testTBL1 VALUES(1, '홍길동', 25)
INSERT INTO testTBL1 VALUES(id, userName) Values(2, '설현')
자동으로 증가하는 IDNTITY
테이블의 속성이 IDENTITY로 지정되어 있다면, INSERT에서는 해당 열이 없다고 생각하고 입력하면 된다. IDENTITY는 자동으로 1부터 증가하는 값을 입력해준다. 또, TABLE에서 DEFAULT문장으로 기본값을 설정했을때, I IDENTITY 지정시에는 입력값을 생략한다.(DEFAULT 값)
강제로 IDNTITY 값을 입력하고 싶다면

CREATE TABLE testTBL2 -- INSERT 구문 테스트용 테이블
(
id INt NOT NULL IDENTITY, -- 자동증가 아이디
userName NCHAR(3), -- 사용자명
age INT, -- 나이
nation NCHAR(4) DEFAULT '대한민국' -- 국가
);
-- nation에 입력을 안하면 대한민국이 기본값으로 들어감
SELECT * FROM testTBL2;
INSERT INTO testTBL2 VALUES ('홍길동', 25, '한국');
INSERT INTO testTBL2 (userName, age) VALUES ('홍길순', 18);
SET IDENTITY_INSERT testTBL2 ON; -- id 자동 증가 취소
INSERT INTO testTBL2(id, userName, age, nation)
VALUES(8, '김동욱', 29, '호주');
-- 위의 3줄은 직접 값을 명시할 수 있음
SET IDENTITY_INSERT testTBL2 OFF; -- id 자동 증가 다시 작동
INSERT INTO testTBL2(userName, age, nation)
VALUES('황진이', 34, NULL);
-- OFF함으로써 id가 max값으로 다시 id가 올라감
SELECT @@IDENTITY; -- 내가 마지막으로 들어간 IDENTITY값을 출력
SELECT IDENT_CURRENT('testTBL2'); -- 테이블의 IDENTITY의 최대값출력
SELECT*FROM testTBL2;
시퀀스
아디덴이랑 비슷한데 과감히 넘어감
데이터 수정(Update문) (254p)
입력되어 있는 테이블을 변경하기위해 사용한다.
유형)
UPDATE 테이블이름
SET 열1 = 값1, 열2 = 값2 ...
WHERE 조건
사용 예)
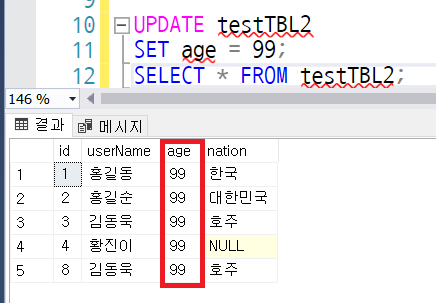
UPDATE testTbl6
SET Lname = '없음'
WHERE Fname = 'Kim';

데이터 삭제(DELETE)
DELETE 테이블 이름 WHERE 조건;

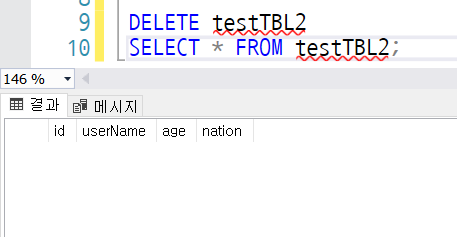
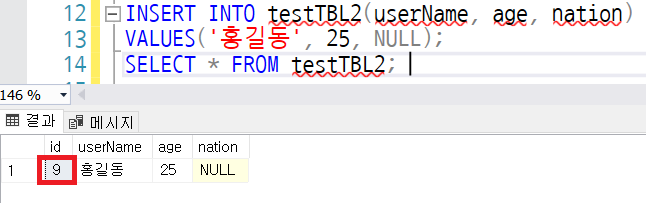
DML문인 DELETE는 트랜잭션 로그를 기록하는 작업때문에 삭제가 오래 걸린다. 수백~수천만 건의 데이터를 삭제할 경우에 한참 동안 삭제할 수도있다. DDL 문인 DROP 문은 트랜잭션 로그를 발생시키지 않으면서 테이블 자체를 삭제한다.
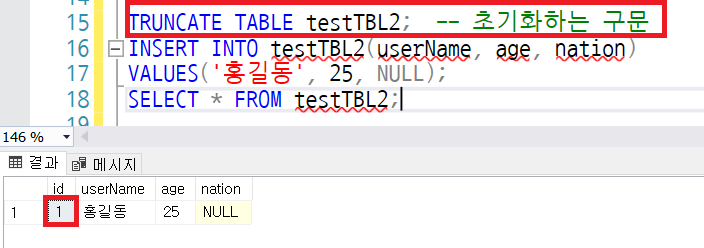
DDL문인 TRUNCATE문의 효과는 DELETE와 동일하지만, 트랜잭션 로그를 기록하지 않아서 속도가 더 빠르다. 그러므로 대용량의 테이블 전체 내용을 삭제한다고 할때, 테이블 자체가 필요없을 경우에는 DROP으로 삭제하고, 테이블 구조는 남겨좋고 싶다면 TRUNCATE로 삭제하는 것이 효율적이다.
Merge
하나의 문장에서 경우에 따라서 INSERT, UPDATE, DELET를 수행할 수 있는 구문
익숙해진 다음에 쓰도록하자(강사님도 입사하고 3년후에 썼다고함)
이제 중요한내용들이 나온다
데이터 형식 : 회사가서도 구글링을 하기때문에 외울필요없다. 대신 쓸줄 알아야함
7장. Transact-SQL 고급
데이터 형식의 종류
데이터형식을 왜 나누냐면 낭비를 최소화하려고 사용한다.
숫자형 데이터 형식
| 데이터 형식 | 바이트 수 | 숫자 범위 | 설명 |
| BIT | 1 | 0 또는 1 또는 NULL | Boolean 형인 참(True,1), 거짓(False,0)에 사용한다. |
| TINYINT | 1 | 0 ~ 255 | 양의 정수 |
| SMALLINT | 2 | -32,768 ~ 32,767 | 정수 |
| INT | 4 | 약 -21억 ~ +21억 | 정수 |
| BIGINT | 8 | -2의 63제곱 ~ +2의63제곱-1 | 정수 |
| DECIMAL(p,[s]) | 5~17 | -1038+1 ~ 1038-1 | 고정 정밀도(p)와 배율(s)을 가진 숫자형이다. 예를 들어 decimal(5,2)는 전체 자릿수를 5자리로 하되, 그 중 소수점 이하를 2자리로 하겠다는 의미다. |
| NUMERIC | 5~17 | -1038 ~ +1038-1 | DECIMAL과 동일한 데이터 형식이다. |
| FLOAT[(n)] | 4~8 | n이 25미만이면 4바이트, 25이상이면 8바이트의 크기를 할당한다. | |
| REAL | 4 | FLOAT(24)와 동일하다. | |
| MONEY | 8 | -2의 63제곱 ~ +2의63제곱-1 | 화폐 단위로 사용한다. |
| SMALLMONEY | 4 | 약 -21억 ~ +21억 | 화폐 단위로 사용한다. |
Decimal(p, s) : 고정 정밀도(p)와 배율(s)을 가진 숫자형이다
-999999.99 부터 999999.99 까지의 숫자를 저장할 경우에는 Decimal(8, 2)로 표현하면 된다.
전체 자릿수를 8자리로 하되, 소수점 이하는 2자리로 하겠다는 의미이다.
FLOAT(n) : n이 25미만이면 5바이트, 25이상이면 8바이트의 크기를 할당한다.
문자 데이터 형식
| 데이터 형식 | 바이트 수 | 설명 |
| CHAR[(n)] | 0~8000 | 고정길이 문자형이다. character의 약자다. |
| NCHAR[(n)] | 0~8000 | 글자로는 0~4000자, 유니코드 고정 길이 문자형으로 National character의 약자다. |
| VARCHAR[(n|max)] | 0~2의 31제곱 - 1 | 가변길이 문자형. n을 사용하면 1~8000까지 크기를 지정할 수 있고, max로 지정하면 최대 2GB 크기를 지정할 수 있다. Variable character의 약자. |
| NVARCHAR[(n|max)] | 0~2의 31제곱 - 1 | 유니코드 가변길이 문자형. n을 사용하면 1~4000까지 크기를 지정할 수 있고, max로 지정하면 최대 2GB 크기를 지정할 수 있다. National Variable character의 약자다. |
| BINARY[(n)] | 0~8000 | 고정길이의 이진 데이터 값이다. |
| VARBINARY[(n|max)] | 0~2의 31제곱 - 1 | 가변길이의 이진 데이터 값이다. n을 사용하면 1~8000까지 크기를 지정할 수 있고, max로 지정하면 최대 2GB 크기를 지정할 수 있다. 이미지/동영상 등을 저장하기 위해 사용된다. Variable Binary의 약자다. |
날짜와 시간 데이터 형식
| 데이터 형식 | 바이트 수 | 설명 |
| DATETIME | 8 | 날짜는 1753-1-1~9999-12-31까지 저장되며, 시간은 00:00:00~23:59:59.997까지 저장된다. 정확도는 밀리초(1/1000초) 단위까지 인식한다. 형식은 'YYYY-MM-DD 시:분:초' 사용된다. |
| DATETIME2 | 6~8 | 날짜는 0001-1-1~9999-12-31까지 저장된다. 시간은 00:00:00~23:59:59.9999999까지 저장된다. 정확도는 100나노초 단위까지 인식한다. 형식은 'YYYY-MM-DD 시:분:초' 사용된다(DATETIME의 확장형으로 생각하면 됨). |
| DATE | 3 | 날짜는 0001-1-1~9999-12-31까지 저장된다. 날짜 형식만 사용된다. 'YYYY-MM-DD' 형식으로 사용된다. |
| TIME | 5 | 00:00:00.0000000~23:59:59.9999999까지 저장. 정확도는 100나노초 단위까지 인식된다. '시:분:초"형식으로 사용된다. |
| DATETIMEOFFSET | 10 | DATETIME2와 거의 비슷하지만, 표준 시간대를 인식하며 24시간제를 기준으로 하는 시간도 표시해준다. 'YYYY-MM-DD 시:분:초 +표준시간'형식으로 사용된다. |
| SMALLDATETIME | 4 | 날짜는 1900-1-1~2079-6-6까지 저장된다. 정확도는 분 단위까지 인식된다. |
기타 데이터 형식
| 데이터 형식 | 바이트 수 | 설명 |
| ROWVERSION | 8 | VARBINARY(8)과 동일하며, 데이터베이스 내에서 자동으로 생성된 고유 이진 숫자롤 표시한다. SQL Server 내부적으로 사용되는 것이라서 신경 쓸 필요는 없다. |
| SYSNAME | 128 | NVARCHAR(128)과 동일하며, 데이터베이스 개체의 이름에 사용된다. SQL Server 내부적으로 사용된다. |
| CURSOR | 1 | T-SQL 커서를 변수로 처리한다. |
| TABLE | N/A | 테이블 자체를 저장한다. 임시 테이블과 비슷한 기능이다. |
| UNIQUEIDENTIFIER | 16 | 복제에서 사용되는 자료형으로, 유일성을 보장하는 GUID 값을 저장한다. |
| SQL_VARIANT | N/A | 다른 데이터 형식의 저장이 가능한 데이터형이다. |
| HIERARCHYID | N/A | 계층 구조가 있는 테이블을 만들거나 다른 위치에 있는 데이터의 계층 구조를 참조할 수 있다. |
| XML | N/A | XML 데이터를 저장하기 위한 형식으로 최대 2GB 저장된다. |
| GEOMETRY/GEOGRAPHY | N/A | 공간 데이터 형식으로 선,점 및 다각형 같은 공간 데이터 개체를 저장하고 조작 할 수 있다. |
사용자 정의 데이터 형식
기존의 데이터 형식에 별칭을 붙이는 것으로, 사용의 편의성을 위해 사용
유형과 예시
CREATE TYPE 사용자정의데이터형식_이름 FROM 기존데이터형식 NULL 또는 NOT NULL
CREATE TYPE myTypeName FROM nchar(10) NULL


유니코드 데이터 <-> 아스키코드
문자 데이터를 저장하고 관리할 경우, 각 국가별 코드 페이지가 달라서 서로 호환되지 않는 문제점을 해결
데이터형식은 nchar, nvarchar, ntext가 있다.
입력시에는 N'문자열'형식으로 사용하는 것을 권장한다.


INSERT INTO uniTestTBL (korName, engName, code) VALUES (N'박신혜','PSH','NMEU0010');
INSERT INTO uniTestTBL (korName, engName, code) VALUES ('성명건','SMG','NMEU0014');
SELECT * FROM uniTestTBL;
변수의 사용
일시적으로 사용되며, 실행 후에는 바로 소멸됨
사용 형식)
변수의 선언 : DECLARE @변수이름 데이터형식;
변수에 값 대입 : SET @변수이름 = 변수의 값;
변수의 값 출력 : SELECT @ 변수이름;DECLARE @myVar1 INT;
DECLARE @myVar2 SMALLINT, @MYVAR3 DECIMAL(5,2);
SET @myVar1 = 10;
SET @myVar2 = 170;
SET @MYVAR3 = 3.14;
--SELECT @myVar1 AS 'myVar1값'; -- 열의 이름을 myVar1값으로 바꿈
-- SELECT @myVar2, @myVAR3
SELECT @MYVAR3, name, height FROM userTBL
WHERE height > 170;
SELECT TOP(@MYVAR1) name, height FROM userTBL
WHERE height > @myVar2;

DECLARE @myVar1 INT;
SET @myVar1 = 3;
SELECT TOP(@myvar1) name, height FROM userTBL WHERE height > 170;
데이터형 변환 함수(277p)
데이터의 형식을 변환해 주는 함수
- CAST ( expression AS 데이터 형식 [ (길이) ])
- CONVERT ( 데이터 형식[(길이)], expression [ , 스타일])
- TRY_CONVERT ( 데이터형식[(길이)], expression [ , 스타일])
- PARSE (문자열 AS 데이터 형식)
- TRY_PARSE (문자열 AS 데이터 형식)
ex)


구성함수
| 함수 | 설명 |
| @@LANGID @@LANGUAGE |
현재 설정된 언어의 코드 번호 및 언어를 확인할 수 있다. <예> select @@LANGID; 한국어의 경우에는 29가 출력된다. 다른 언어의 ID는 sp_helplanguage 저장 프로시저를 실행하면 확인할 수 있다. |
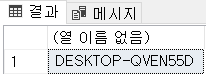
| @@SERVERNAME | 현재 인스턴스의 이름을 확인할 수 있다. <예> SELECT @@SERVERNAME; |
| @@SERVICENAME | 서비스의 이름을 돌려준다. <에> SELECT @@SERVICENAME; 기본 인스턴스인 경우에는 MSSQLSERVER를 들려주고, 명명된 인스턴스의 경우에는 설치할 때 지정한 인스턴스 이름을 돌려준다. |
| @@SPID | 현재 사용자 프로세스의 세션 ID를 반환한다. <예> SELECT @@SPID AS 'ID', SYSTEM_USER AS [로그인사용자], USER AS [사용자] ; 현재 세션 ID번호, 로그인 사용자, 사용자를 돌려준다. |
| @@VERSION | 현재 설치된 SQL Server의 버전, CPU 종류 운영체제 버전의 정보를 알려준다. <예> SELECT @@VERSIONL |
SELECT @@VERSION;
SELECT @@SERVERNAME;
날짜및 시간 함수
| 함수 | 설명 |
| SYSDATETIME() GETDATE() |
현재의 날짜와 시간을 돌려준다. <예> SELECT SYSDATETIME(), GETDATE(); |
| DATEADD() | 날짜에 더한 결과를 돌려준다. <예> SELECT DATEADD(day, 100, '2019/10/10'); 2019년 10월10일부터 100일 후의 날짜를 돌려준다. Day 대신에 year,month,week,hour,minute,second 등이 올 수 있다. |
| DATEDIFF() | 두 날짜의 차이를 돌려준다. <예> SELECT DATEDIFF(week, GETDATE(), '2027/10/19'); 현재부터 2027년 10월19일까지 남은 주를 알려준다. |
| DATENAME() | 날짜의 지정한 부분만 돌려준다. <예> SELECT DATENAME(weekday, '2022/10/19'); 2022년 10월19일이 무슨 요일인지 알려준다. |
| DATEPART() | 지정된 날짜의 연도 또는 월 또는 일을 돌려준다. <예> SELECT DATEPART(year, GETDATE()); 현재 연도를 돌려준다. |
| DAY() MONTH() YEAR() |
지정된 날짜의 일/월/년을 돌려준다. <예> SELECT MONTH('2022/10/19'); 2022년 10월19일의 월인 10을 돌려준다. |
| DATEFROMPARTS() DATETIME2FROMPARTS() DATETIMEFROMPARTS() DATETIMEOFFSETFROMPARTS() SMALLDATETIMEFROMPARTS() TIMEFROMPARTS() |
문자열을 각각 입력하면 해당하는 데이터 형식의 값을 반환한다. 예를 들어, DATEFROMPARTS()는 연,월,일을 입력하면 DATE 값을 반환한다. <예> SELECT DATEFROMPARTS('2022','10','19'); '2022-10-19'을 돌려준다. |
| EOMONTH() | 입력한 날짜에 포함된 달의 마지막 날을 돌려준다. <예> SELECT EOMONTH('2019-3-3'); 2019년 3월의 마지막 날짜를 돌려준다. <예> SELECT EOMONTH(GETDATE(), 3); 오늘 날짜에서 3개월 후의 마지막 날짜를 돌려준다. |
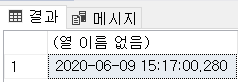
SELECT GETDATE();
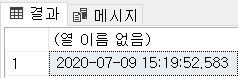
SELECT DATEADD(MONTH,1,GETDATE());
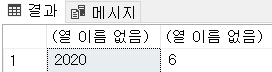
SELECT YEAR(GETDATE()),MONTH(GETDATE());
수치연산함수
| 함수 | 설명 |
| ABS() | 수식의 절대값을 돌려준다. <예> SELECT ABS(-100); 절대값인 100을 돌려준다. |
| ROUND() | 자릿수를 올려서 돌려준다. <예> SELECT ROUND(1234.5678, 2), ROUND(1234,5678, -2); 1234.5700과 1200.0000을 돌려준다. |
| RAND() | 0~1까지의 임의의 숫자를 돌려준다. <예> SELECT RAND(); |
| SQRT() | 제곱근값을 돌려준다. <예> SELECT SQRT(10); 10의 제곱근인 약 3.16을 돌려준다. |
| POWER() | 거듭제곱값을 돌려준다. <에> SELECT POWER(3,2); 3의 2제곱인 9를 돌려준다. |


메타데이터함수
:쓸일많이없음
논리함수
:읽어만보자
문자열 함수(많이쓰임)
| 함수 | 설명 |
| ASCII() CHAR() |
문자의 아스키 코드 값을 돌려주거나 아스키 코드값의 문자를 돌려준다(0~255 범위). <예> SELECT ASCII('A'), CHAR(65); 65와 'A'를 돌려준다. |
| CONCAT() | 둘 이상의 문자열을 연결한다. 이전 버전에서는 대신 "+"로 문자열을 연결하면 된다. <예> SELECT CONCAT('SQL','SERVER',2016); SELECT 'SQL'+'SERVER'+2016; SQLSERVER2016을 돌려준다. |
| UNICODE() NCHAR() |
문자의 유니코드값을 돌려주거나 유니코드값의 문자를 돌려준다(0~63365 범위). <예> SELECT UNICODE('가'), NCHAR(44032); 44032와 '가'를 돌려준다. |
| CHARINDEX() | 문자열의 시작 위치를 돌려준다. <에> SELECT CHARINDEX('SERVER', 'SQL SERVER 2016'); 5를 돌려준다. |
| LEFT() RIGHT() |
왼쪽/오른쪽/지정 위치부터 지정한 수만큼을 돌려준다. <예> SELECT LEFT('SQL SERVER 2016',3), RIGHT('SQL SERVER 2016',4); 'SQL'과 '2016'을 돌려준다. |
| SUBSTRING() | 지정된 위치부터 지정한 개수의 문자를 돌려준다. <에> SELECT SUBSTRING(N'대한민국만세',3,2); 3번째부터 2글자인 '민국'을 돌려준다. |
| LEN() | 문자열의 길이를 돌려준다. <예> SELECT LEN('SQL SERVER 2016'); 글자수인 15를 돌려준다. |
| LOWER() UPPER() |
소문자를 대문자로, 대문자를 소문자로 변경한다. <예> SELECT LOWER('ABCDE'), UPPER('abcde'); 'abcde','ABCDE'를 돌려준다. |
| TRIM() LTRIM() RTRIM() |
왼쪽 공백문자 및 오른쪽 공백문자를 제거해준다. <예> SELECT LTRIM(' 공백앞뒤두개 '_), RTRIM(' 공백앞뒤두개 '); '공백앞뒤두개 '와 ' 공백앞뒤두개'를 돌려준다. |
| REPLACE() | 문자열의 내용을 지정한 것으로 찾아서 바꾼다. <예> SELECT REPLACE('SQL SERVER 2016', 'SERVER', '서버'); 'SQL 서버 2016'을 돌려준다. |
| REPLICATE() | 문자열을 지정한 수만큼 반복한다. <예> SELECT REPLICATE('SQL', 5); 'SQL'을 5번 반복하여 돌려준다. |
| REVERSE() | 문자열의 순서를 거꾸로 만든다. <예> SELECT REVERSE('SQL SERVER 2016'); '6102 REVRES LQS'를 돌려준다. |
| SPACE() | 공백을 지정한 수만큼 반복한다. <예> SELECT SPACE(5); ' '(공백5개)를 돌려준다. |
| STR() | 숫자를 문자로 변환한다(CAST나 CONVERT를 대신 사용 권장). |
| STUFF() | 문자를 지정한 위치의 개수만큼 삭제한 후에, 새로운 문자를 끼워넣는다. <예> SELECT STUFF ('SQL 서버 2016',5,2,'SERVER'); 'SQL SERVER 2016'을 돌려준다. |
| FORMAT() | 지정된 형식으로 출력한다. 표준 형식은 FORMAT(value, format)을 갖는데, value는 출력할 값이고, format은 출력할 형식이다. <예> SELECT FORMAT(GETDATE(), 'dd/MM/yyyy'); 현재 날짜의 "일-월-연도"를 돌려준다. |




순위함수
순번을 처리하기 위해서 필요했던 복잡한 과정들을 단순화 시켜서 쿼리의 작성시간을 단축시켜 준다.
사용 형식)
<순위함수이름>() OVER(
[PARTITION BY <partition_by-list>]
ORDER BY <order_by_list>


분석함수는 넘어갔음
PIVOT / UNPIVOT 연산자
PIVOT 연산자는 한 열에 포함된 여러 값을 출력하고, 이를 여러 열로 변환하여 테이블 반환 식을 회전하고 필요하면 집계까지 수행할 수 있다. UNPIVOT은 PIVOT에 반대되는 연산을 수행한다.(근데 UNPIVOT은 거의안씀)
사용유형)
PIVOT (집계함수(열)
FOR 새로운 열로 변경할 열이름
IN (열 목록) AS 피벗이름)
CREATE TABLE pivotest
(
uName NCHAR(3),
season NVARCHAR(2),
amount INT
);
INSERT INTO pivotest VALUES
('김범수', '겨울', 10),
('윤종신', '여름', 15),
('김범수', '가을', 25),
('김범수', '봄', 3),
('김범수', '봄', 37),
('윤종신', '겨울', 25),
('김범수', '여름', 14),
('김범수', '겨울', 22),
('윤종신', '여름', 64)
SELECT * FROM pivotest
PIVOT(SUM(amount)
FOR season
IN([봄],[여름],[가을],[겨울])) AS resultPivot;

JSON 데이터
JSON은 현대의 웹과 모바일 응용프로그램 등과 데이터를 교환하기 위한 개방형 표준 포맷을 말하는데, 속성(Key)과 값(Value)으로 쌍을 이루며 구성되어 있다. 자바스크립트언어에서 파생되었지만, 특정한 언어에 종속 되어있지 않은 독립적인 데이터 포맷이라고 생각하면된다.

[
{"name":"김범수","height":182},
{"name":"임재범","height":182},
{"name":"이승기","height":182},
{"name":"성시경","height":186}
]
(참고로 이 데이터에 주석같은것도 달면 오류가 뜬다)
키가 180이상인 사람의 이름과 키를 나타낸다.
위의 코드를 그대로 복사해서
DECLARE @json NVARCHAR(MAX)
SET @json = N'{ "userTBL" :
[
{"name":"임재범","height":182},
{"name":"이승기","height":182},
{"name":"성시경","height":186}
]
}'; -- 이게 DB로 들어온 데이터
--SELECT ISJSON(@json);
--SELECT JSON QUERY(@json, '$.userTBL[0]');
--SELECT JSON_VALUE(@json, '$.userTBL[0].name');
INSERT INTO tempUser
SELECT * FROM OPENJSON(@json, '$.userTBL')
WITH(
name NCHAR(8) '$.name',
height INT '$.height'
);
SELECT * FROM tempUser
/*
SELECT name, height INTO tempUser
FROM userTBL;
SELECT * FROM tempUser;
DELETE tempUser
*/

T userID, name,
mobile1 + mobile2 AS mobile
INTO newUserTbl2 -- INTO이 나오면 출력은안됨(영향을받음으로뜸)
FROM userTBL
WHERE mobile1 IS NOT NULL; -- NULL이아닌사람만 NEWUSERTbl2에 넣음
SELECT * FROM newUserTbl2;
INSERT INTO newUserTbl2 -- 테이블이 있는 상태에서 셀렉트로 내가 원하는 결과를 넣는다
SELECT userID, name,
mobile1 + mobile2 AS mobile
FROM userTBL
WHERE addr = '서울';
셀렉트는 테이블을 만드는거
뷰는 가상개념(위치가 다름) 테이블의 데이터가 없는데 뷰라는 개념을써서 어떤 테이블을 바라보고 있는 가상의 테이블이다.(보기만 하는거임) 바로가기랑 똑같은 개념
셀렉트는
인투 다음에 있는 테이블이 없는상태이다. 만들면서 집어넣는거임(테이블이 없음)
인서트
테이블은 있음, 내가 원하는 데이터가없는데 그 셀렉트를 이용해서 원하는 결과를 넣는거임
꿀팁)
컨트롤 K + C로 한꺼번에 주석처리
컨트롤 K + U로 한꺼번에 주석해제
'개발자과정준비 > 데이터베이스(DB)' 카테고리의 다른 글
| [DB] 5. 인덱스, 트랜잭션, 데이터베이스 모델링, 저장 프로시저, 사용자 정의 함수 (0) | 2020.06.12 |
|---|---|
| [DB] 4. JOIN, UNION, SQL프로그래밍, 테이블, 뷰 (0) | 2020.06.10 |
| [DB] 2. 운영 실습, SELECT 문 (0) | 2020.06.08 |
| [DB] 1. DBMS 개요, DB 생성 실습 (0) | 2020.06.08 |
| [DB] 0. SQL Server 및 SSMS 설치 (0) | 2020.06.07 |
