쓰레드 동기화
쓰레드는 실행결과를 저장하기전에 레지스터에 접근해서 값을 건드려서 우리가 원하지 않는 결과가 출력된다.
쓰레드가 지니는 문제점을 살펴보았으니, 해결책을 고민할 차례이다. 참고로 이 해결책을 가리켜 "쓰레드 동기화(Synchroniztion)'라 한다.
동기화의 두가지 측면
쓰레드의 동기화는 쓰레드의 접근 순서 때문에 발생하는 문제점의 해결책을 뜻한다. 그런데 동기화가 필요한 상황은 2가지 측면에서 생각해볼 수 있다.
- 동일한 메모리 영역으로의 동시접근이 발생하는 상황
- 동일한 메모리 영역에 접근하는 쓰레드의 실행순서를 지정해야하는 상황
첫번째 언급한 상황은 이미 충분히 설명되었으니, 두번째 언급한 상황에 대해서 알아보자.
이는 쓰레드의 '실행순서 컨트롤(Control)'에 관련된 내용이다.
예를들어 쓰레드 A, B가 있다고 가정해보자.
그런데 쓰레드 A는 메모리 공간에 값을 가져다 놓는(저장하는) 역할을 담당하고,
쓰레드 B는 이 값을 가져가는 역할을 담당한다고 가정해보자.
이러한 경우 쓰레드 A가 약속된 메모리 공간에 먼저 접근을해서 값을 저장해야 한다. 혹시라도 쓰레드 B가 먼저 접근을 해서 값을 가져가면, 잘못된 결과로 이어질 수 있다. 이렇듯 실행 순서의 컨트롤이 필요한 상황에서도 이어서 설명하는 동기화 기법이 활용된다.
우리는 '뮤텍스(Mutex)'와 '세마포어(Semaphore)' 라는 두 가지 동기화 기법에 대해 알아볼 것이다.
그런데 이 둘은 개념적으로 매우 유사하다. 따라서 뮤텍스를 이해하고나면 세마포어는 쉽게 이해할 수 있따.
뿐만 아니라 대부분의 동기화 기법이 유사하기 때문에 여기서 설명하는 내용을 잘 이해하면 이후의 Chapter에서 설명하는 윈도우 기반의 동기화 기법도 쉽게 이해 및 활용이 가능하다.
뮤텍스(Mutex)
뮤텍스란 'Mutual Exclusion'의 줄임 말로써 쓰레드의 동시접근을 허용하지 않는다는 의미가 있다.
그리고 그 이름처럼 뮤텍스는 쓰레드의 동기접근에 대한 해결책으로 주로 사용된다. 그럼 뮤텍스의 이해를 위해 다음 대화를 관찰하자.
동수 : (똑똑) 안에 누구 계세요?
응수 : 네. 지금 볼일보고 있습니다.
동수 : (똑똑)
응수 : 곧 나갑니다.
대충 어떤 상황을 묘사했는지 쉽게 파악이 되었을 것이다. 현실세계에서의 임계영역은 화장실과 같다고 볼 수 있다.
화장실에 둘 이상의 사람(쓰레드의 비유)이 동시에 들어갈 수는 없을 것이다. 때문에 우리는 임계영역을 화장실에 비유해서 이해할 수 있다. 그리고 여기서 일어나는 모든 일들은 임계영역의 동기화에서 거의 그대로 표현된다.
다음은 화장실 사용의 일반적인 규칙이다.
- 화장실의 접근보호를 위해서 들어갈 때 문을 잠그고 나올때 문을 연다.
- 화장실이 사용 중이라면, 밖에서 대기 해야한다.
- 대기중인 사람이 둘 이상 될 수 있고, 이들은 대기 순서에 따라 화장실에 들어갈 수 있다.
위의 규칙은 화장실의 접근규칙이다. 마찬가지로 쓰레드도 임계영역의 보호를 위해서는 위의 규칙이 반영되어야한다.
그럼 화장실에는 있고, 우리가 앞서 구현한 쓰레드 관련 예제에는 없는 것이 무엇일까? 그것은 바로 자물쇠 시스템이다.
즉, 화장실에 들어갈때 문을 잠그고, 나갈때 여는 그러한 자물쇠 시스템이 쓰레드의 동기화에 필요하다. 그리고 지금 설명하려는 뮤텍스는 매우 훌륭한 자물쇠 시스템이다. 그럼 이어서 뮤텍스라 불리는 자물쇠 시스템의 생성 및 소멸 함수를 알아보자.
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex)
// 성공 시 0, 실패 시 0 이외의 값 반환- mutex : 뮤텍스 생성시에는 뮤텍스의 참조 값 저장을 위한 변수의 주소 값 전달, 그리고 뮤텍스 소멸시에는 소멸하고자하는 뮤텍스의 참조 값을 저장하고 있는 변수의 주소 값 전달
- attr : 생성하는 뮤텍스의 특성정보를 담고 있는 변수의 주소 값 전달, 별도의 특성을 지정하지 않을 경우에는 NULL 전달.
위 함수들을 통해서도 확인할 수 있듯이, 자물쇠 시스템에 해당하는 뮤텍스의 생성을 위해서는 다으모가 같이 pthread_mutex_t형 변수가 하나 선언되어야한다.
pthread_mutex_t mutex;그리고 이 변수의 주소 값은 pthread_mutex_init 함수 호출 시 인자로 전달되어서, 운영체제가 생성한 뮤텍스(자물쇠 시스템)의 참조에 사용된다. 때문에 pthread_mutex_destroy 함수 호출 시에도 인자로 사용되는 것이다.
참고로 뮤텍스 생성시 별도의 특성을 지정하지 않아서 두 번째 인자로 NULL을 전달하는 경우에는 매크로 PTHREAD_MUTEX_INITIALIZER을 이용해서 다음과 같이 초기화 하는 것도 가능하다.
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;하지만 가급적이면 pthread_mutex_init 함수를 이용한 초기화를 추천한다. 왜냐하면 매크로를 이용하는 초기화에는 오류발생에 대한 확인이 어렵다. 그럼 이어서 뮤텍스를 이용해서 화장실에 비유되는 임계영역에 설치된 자물쇠를 걸어 잠그거나 풀때 사용하는 함수를 알아보자.
#include <pthread.h>
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex); // 성공 시 0, 실패 시 0 이외의 값 반환함수의 이름에도 lock, unlock이 있으니 쉽게 의미하는 바를 알 수 있을 것이다.
임계영역에 들어가기에 앞서 호출하는 함수가 pthread_mutex_lock이다. 이 함수를 호출할 당시 다른 쓰레드가 이미 임계영역을 실행하고 있는 상황이라면, 이 쓰레드가 pthread_mutex_unlock 함수를 호출하면서 임계영역을 빠져나갈 때까지 pthread_mutex_lock 함수는 반환하지 않는다. 즉, 다른 쓰레드가 임계영역을 빠져나갈 때까지 블로킹 상태에 놓이게 된다.
그럼 임계영역을 보호하기 위한 코드의 구성을 간단히 정리해보자.
뮤텍스가 이미 생성된 상태에서는 다음의 형태로 임계영역을 보호하게 된다.
pthread_mutex_lock(&mutex);
// 임계영역 시작
// ....
// 임계영역 끝
pthread_mutex_unlock(&mutex);쉽게 말해서 lock, 그리고 unlock 함수를 이용해서 임계영역의 시작과 끝을 감싸는 것이다.
그러면 이것이 임계영역에 대한 자물쇠 역할을 하면서, 둘 이상의 쓰레드 접근을 허용하지 않게 된다.
한가지 더 기억해야 할 것은, 임계영역을 빠져나가는 쓰레드가 pthread_mutex_unlock 함수를 호출하지 않는다면,
임계영역으로의 진입을 위해 pthread_mutex_lock 함수는 블로킹 상태에서 빠져나가지 못하게 된다는 사실이다.
이를 두고 '데드락(Dead-lock)' 상태라 하는데, 이러한 상황이 발생하지 않도록 주의해야 한다.
그럼 이어서 뮤텍스를 이용해서 예제 thread4.c에서 보인 문제점을 해결해보자.
// mutex.c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
#define NUM_THREAD 100
void * thread_inc(void * arg);
void * thread_des(void * arg);
long long num = 0; // long long형은 64비트 정수 자료형
pthread_mutex_t mutex;
int main(int argc, char *argv[])
{
pthread_t thread_id[NUM_THREAD];
int i;
pthread_mutex_init(&mutex, NULL);
for(i = 0; i < NUM_THREAD; i++)
{
if(i % 2)
pthread_create(&(thread_id[i]), NULL, thread_inc, NULL);
else
pthread_create(&(thread_id[i]), NULL, thread_des, NULL);
}
for(i = 0; i < NUM_THREAD; i++)
pthread_join(thread_id[i], NULL);
printf("result : %lld \n", num);
pthread_mutex_destroy(&mutex);
return 0;
}
void * thread_inc(void *arg)
{
int i;
pthread_mutex_lock(&mutex);
for(i = 0; i<50000000; i++)
num += 1;
pthread_mutex_unlock(&mutex);
return NULL;
}
void * thread_des(void * arg)
{
int i;
for(i = 0; i<50000000; i++)
{
pthread_mutex_lock(&mutex);
num -= 1;
pthread_mutex_unlock(&mutex);
}
return NULL;
}
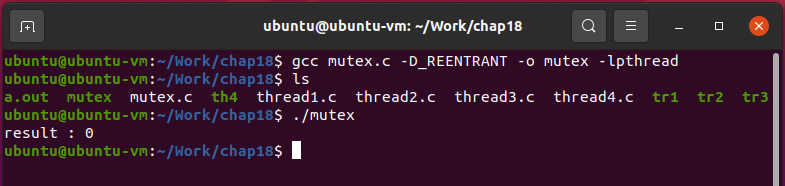
실행결과를 보면, 예제 thread4.c에 있는 문제점이 해결되어서 result : 0이 출력되었다.
그런데 실행결과를 확인하기까지 오랜 시간이 걸렸다.
왜냐하면 뮤텍스의 lock, unlock 함수의 호출에는 생각보다 오랜 시간이 걸리기 때문이다.
thread_inc 함수의 동기화를 알아보자.
void * thread_inc(void *arg)
{
int i;
pthread_mutex_lock(&mutex);
for(i = 0; i < 50000000; i++)
{
num+=1;
pthread_mutex_unlock(&mutex);
return NULL;
}
이는 임계영역을 상대적으로 좀 넓게 잡은 경우이다. 그런데 이유없이 넓게 잡은 것은 아니고 다음의 장점을 생각한 결과이다.
"뮤텍스의 lock, unlock 함수의 호출 수를 최대한으로 제한한다"
위 예제의 thread_des 함수는 thread_inc 함수보다 뮤텍스의 lock, unlock 함수를 49,999,999회 더 호출하는 구조이다.
때문에 인간이 느끼고도 남을 정도의 큰 속도 차를 보인다. 따라서 쓰레드의 대기 시간이 문제 되지 않는 상황이라면, 위의 경우에는 임계영역을 넓게 잡아주는 것이 좋다. 하지만 변수 num의 값 증가가 50,000,000회 진행될 때까지 다른 쓰레드의 접근을 허용하지 않기 때문에 이는 단점으로 작용할 수 있다.
세마포어(Semaphore)
세마포어는 뮤텍스와 매우 유사하다. 따라서 뮤텍스에서 이해한 내용을 바탕으로 수비게 세마포어를 이해 할 수 있다.
참고로 여기서는 0과 1만 사용하는 '바이너리 세마포어'라는 것을 대상으로 쓰레드의 '실행 순서 컨트롤' 중심의 동기화를 알아보자. 다음은 세마포어의 생성 및 소멸에 관한 함수이다.
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_destroy(sem_t *sem); // 성공 시 0, 실패 시 0 이외의 값 반환- sem : 세마포어 생성시에는 세마포어의 참조 값 저장을 위한 변수의 주소 값 전달, 그리고 세마포어 소멸 시에는 소멸하고자 하는 세마포어의 참조 값을 저장하고 있는 변수의 주소 값 전달
- pshared : 0 이외의 값 전달 시, 둘 이상의 프로세스에 의해 접근 가능한 세마포어 생성, 0 전달시 하나의 프로세스 내에서만 접근 가능한 세마포어 생성, 우리는 하나의 프로세스 내에 존재하는 쓰레드의 동기화가 목적이므로 0을 전달한다.
- value : 생성되는 세마포어의 초기 값 지정.
위의 함수에서 매개변수 pshared는 우리의 관심영역 밖이므로 0을 전달하기로 하자. 그리고 매개변수 value에 의해 초기화되는 세마포어의 값이 무엇인지는 잠시 후에 알게 될 것이다.
그럼 이어서 뮤텍스의 lock, unlock 함수에 해당하는 세마포어 관련 함수를 알아보자.
#include <semaphore.h>
int sem_post(sem_t *sem);
int sem_wait(sem_t *sem); // 성공 시 0, 실패 시 0 이외의 값 반환- sem : 세마포어의 참조 값을 저장하고 있는 변수의 주소 값 전달, sem_post에 전달되면 세마포어의 값은 하나 증가, sem_wait에 전달되면 세마포어의 값은 하나 감소
sem_init 함수가 호출되면 운영체제에 의해 세마포어 오브젝트라는 것이 만들어 지는데, 이곳에는 '세마포어 값(Semaphore Value)'라 불리는 정수가 하나 기록된다. 그리고 이 값은 sum_post 함수가 호출되면 1 증가하고, sem_wait 함수가 호출되면 1 감소한다.
단, 세마포어의 값은 0보다 작아질 수 없기 때문에 현재 0인 상태에서 sem_wait 함수를 호출하면, 호출한 쓰레드는 함수가 반환되지 않아서 블로킹 상태에 놓이게 된다. 물론 다른 쓰레드가 sem_post 함수를 호출하면 세마포어의 값이 1이 되므로, 이 1을 0으로 감소시키면서 블로킹 상태에 빠져나가게 된다.
바로 이러한 특징을 이용해서 임계영역을 동기화 시키게 된다. 즉, 다음의 형태로 임계영역을 동시화 시킬 수 있다.
(이때 세마포어의 초기 값이 1이라 가정한다)
sem_wait(&sem) // 세마포어 값을 0으로..
// 임계영역 시작
// ...
// 임계영역 끝
sem_post(&sem) // 세마포어 값을 1로...위와 같이 코드를 구성하면, sem_wait 함수를 호출하면서 임계영역에 진입한 쓰레드가 sem_post 함수를 호출하기 전까지는 다른 쓰레드에 의해서 임계영역의 진입이 허용되지 않는다. 그리고 세마포어 값은 0과 1을 오가게 되는데, 이러한 특징 때문에 위와 같은 구성을 가리켜 바이너리 세마포어라 하는 것이다.
그럼 이어서 세마포어 관련 예를 보이겠다. 그런데 이번에는 동시접근 동기화가 아닌, 접근 순서의 동시과화 관련된 예제를 작성해보이겠다. 예제의 시나리오는 다음과 같다.
"쓰레드 A가 프로그램 사용자로부터 값을 입력 받아서 전역 변수 num에 저장하면,
쓰레드 B는 이 값을 가져다가 누적해 나간다. 이 과정은 총 5회 진행되고, 진행이 완료되면 총 누적금액을 출력하면서 프로그램은 종료된다. "
위의 시나리오대로 프로그램을 구현하려면 변수 num의 접근은 쓰레드 A, 쓰레드 B의 순으로 이뤄져야 한다.
그리고 이를 위해서는 동기화가 필요하다. 예제를 작성해보자
// semaphore.c
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
void * read(void * arg);
void * accu(void * arg);
static sem_t sem_one;
static sem_t sem_two;
static int num; // 하나씩 입력받을 전역 변수
int main(int argc, char *argv[])
{
pthread_t id_t1, id_t2;
// 세마포어 두개 생성 => 하나는 0이고, 하나는 1이다.
sem_init(&sem_one, 0, 0); // 0으로 초기화 => 키를 갖고있지 않음 => 임계영역 접근 불가능
sem_init(&sem_two, 0, 1); // 1로 초기화 => 키를 갖고있음 => 임계영역 접근 가능
pthread_create(&id_t1, NULL, read, NULL);
pthread_create(&id_t2, NULL, accu, NULL);
pthread_join(id_t1, NULL);
pthread_join(id_t2, NULL);
sem_destroy(&sem_one);
sem_destroy(&sem_two);
return 0;
}
void * read(void * arg)
{
int i;
for(i = 0; i < 5; i++)
{
fputs("Input num: ", stdout);
// 세마포어 변수 sem_two를 이용한 wait와 post 함수 호출
// 세마포어 변수 sem_one을 이용한 wait과 post 함수 호출
sem_wait(&sem_two); // wait를 통해 sem_two의 값을 1을 감소시킴 -> 키획득
scanf("%d", &num);
sem_post(&sem_one); // sem_one이 키를 획득 => 값이 1 증가
}
return NULL;
}
void * accu(void * arg)
{
int sum = 0, i; // num을 누적시킬 변수
for(i = 0; i < 5; i++)
{
sem_wait(&sem_one); // 키를 얻기위해 wait 호출 => 근데 키가 없음 => num에 접근 불가능
sum += num;
sem_post(&sem_two); // sem_one의 키가 sem_two한테 반납
}
printf("Result : %d \n", sum);
return NULL;
}
// 두개의 세마포어를 통해 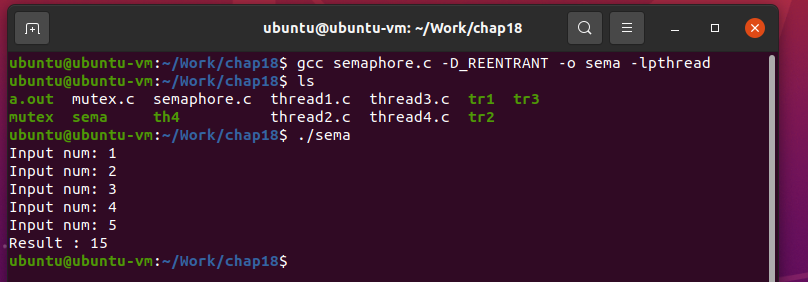
위 예제의 주목해야할 부분들은 다음과 같다.
sem_wait(&sem_two), sem_post(&sem_two)이는 accu 함수를 호출하는 쓰레드가 값을 가져가지도 않았는데, read 함수를 호출하는 쓰레드가
값을 다시 가져다 놓는(이전 값을 덮어쓰는) 상황을 막기 위한 것이다.
sem_post(&sem_one), sem_wait(&sem_one)이는 read 함수를 호출하는 쓰레드가 새로운 값을 가져다 놓기도 전에 accu 함수가 값을 가져가 버리는
(이전 값을 다시 가져가는) 상황을 막기 위한 것이다.
세마포어를 주석처리하고 실행하면 다음과 같이 실행된다.
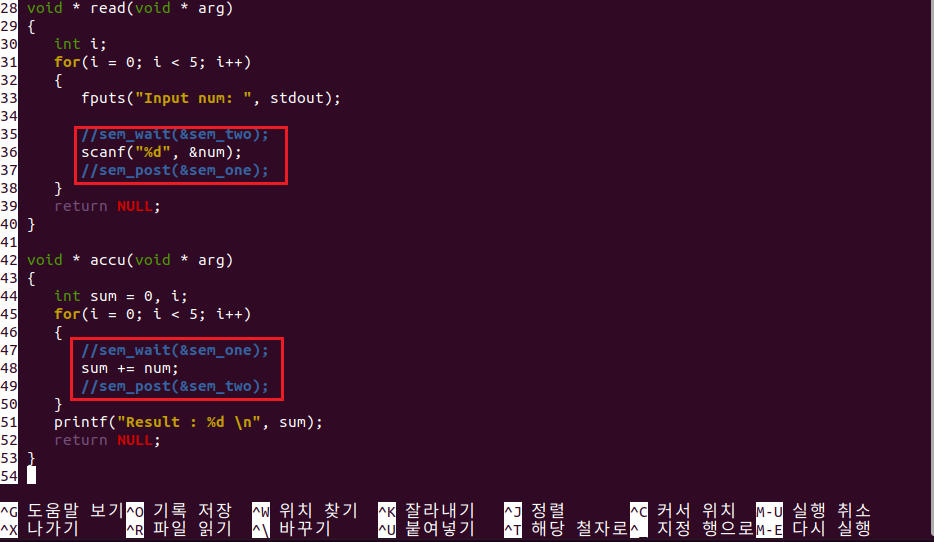
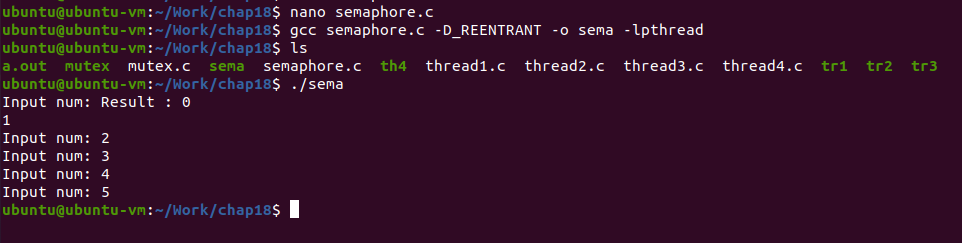
쓰레드의 소멸과 멀티쓰레드 기반의 다중접속 서버의 구현
지금까지는 쓰레드의 생성과 컨트롤에 대해서만 언급하였다. 하지만 이것 못지않게 중요한 것이 쓰레드의 소멸이다.
그래서 먼저 쓰레드의 소멸에 대해 이야기하고 그 다음에 멀티쓰레드 기반으로 서버를 구현해보자.
쓰레드를 소멸하는 두 가지 방법
리눅스의 쓰레드는 처음 호출하는, 쓰레드는 main 함수를 반환했다고 해서 자동으로 소멸되지 않는다.
때문에 다음 두 가지 방법 중 하나를 선택해서 쓰레드의 소멸을 직접적으로 명시해야한다. 그렇지 않으면 쓰레드에 의해서 할당된 메모리 공간이 계속해서 남아있게 된다.
- pthread_join 함수의 호출
- pthread_detach 함수의 호출
pthread_join은 앞서 우리가 호출했던 함수이다. 이렇듯 이 함수가 호출되면, 쓰레드의 종료를 대기할 뿐만 아니라, 쓰레드의 소멸까지 유도가 된다. 하지만 이 함수의 문제점은 쓰레드가 종료될 때까지 블로킹 상태에 놓이게 된다는 점이다. 따라서 일반적으로는 다음 함수의 호출을 통해서 쓰레드의 솜려을 유도한다.
#include <pthread.h>
int pthread_detach(pthread_t thread); // 성공 시 0, 실패 시 0 이외의 값 반환thread : 종료와 동시에 소멸시킬 쓰레드의 ID 정보 전달
위 함수를 호출했다고 해서 종료되지 않은 쓰레드가 종료되거나, 블로킹 상태에 놓이지는 않는다. 따라서 이 함수를 통해서 쓰레드에게 할당된 메모리의 소멸을 유도할 수 있다. 그리고 이 함수가 호출된 이후에는 해당 쓰레드를 대상으로 pthread_join 함수의 호출이 불가능하니, 이점에 주의해야한다. 참고로 쓰레드를 생성할 때 소멸의 시기를 결정하는 방법도 있으나, pthread_detach 함수를 호출하는 방법과 결과적으로 차이가 없어서 여기서는 소개하지 않았다.
그럼 이어서 작성할 멀티쓰레드 기반의 다중접속 서버에서는 쓰레드의 소멸과 관련된 부분도 신경써보자.
멀티쓰레드 기반의 다중접속 서버의 구현
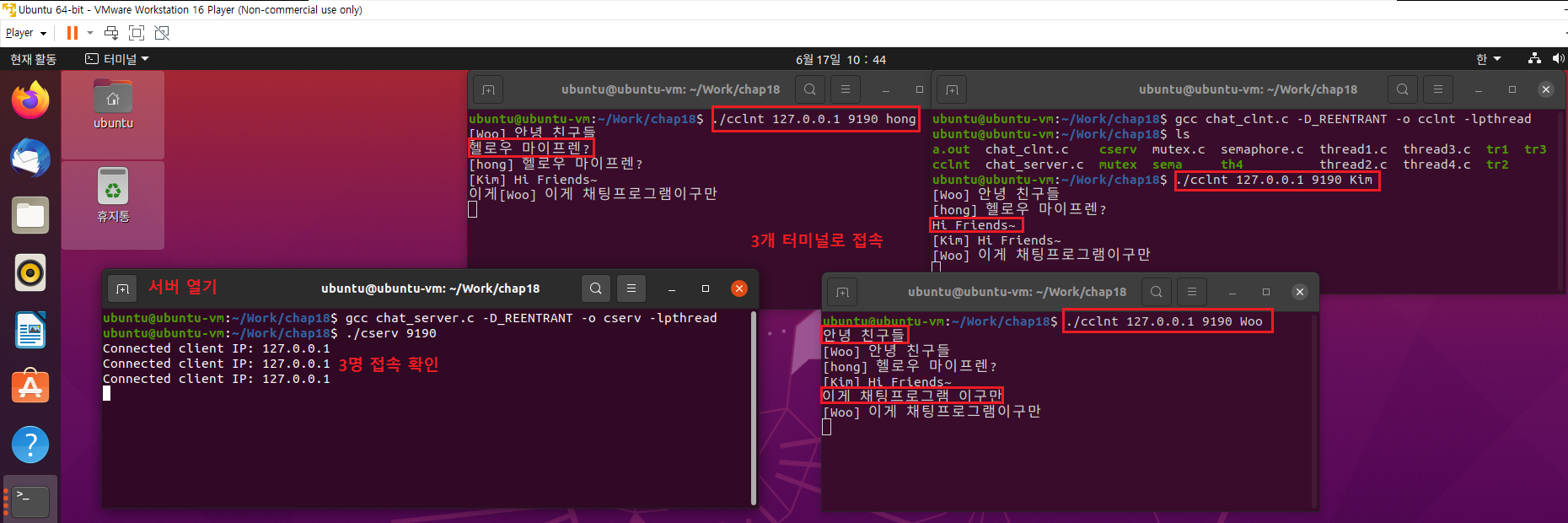
이번에는 에코 서버가 아닌, 서버에 접속한 클라이언트 사이에서 메시지를 주고받을 수 있는 간단한 채팅 프로그램을 만들어보자. 이 예제를 통해 쓰레드가 어떻게 사용되는지, 그리고 동기화는 어떠한 방식으로 처리하는지 확인해보자,
// char_server.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <pthread.h>
#define BUF_SIZE 100
#define MAX_CLNT 256
void * handle_clnt(void * arg);
void send_msg(char * msg, int len);
void error_handling(char * msg);
int clnt_cnt=0; // 서버에 접속한 클라이언트의 소켓 관리를 위한 변수와 배열
int clnt_socks[MAX_CLNT]; // 이 둘은 접근과 관련있는 코드가 임계영역을 구성하게 됨에 주목하자.
pthread_mutex_t mutx;
int main(int argc, char *argv[])
{
int serv_sock, clnt_sock;
struct sockaddr_in serv_adr, clnt_adr;
int clnt_adr_sz;
pthread_t t_id;
if(argc!=2) {
printf("Usage : %s <port>\n", argv[0]);
exit(1);
}
pthread_mutex_init(&mutx, NULL);
serv_sock=socket(PF_INET, SOCK_STREAM, 0);
memset(&serv_adr, 0, sizeof(serv_adr));
serv_adr.sin_family=AF_INET;
serv_adr.sin_addr.s_addr=htonl(INADDR_ANY);
serv_adr.sin_port=htons(atoi(argv[1]));
if(bind(serv_sock, (struct sockaddr*) &serv_adr, sizeof(serv_adr))==-1)
error_handling("bind() error");
if(listen(serv_sock, 5)==-1)
error_handling("listen() error");
while(1)
{
clnt_adr_sz=sizeof(clnt_adr);
clnt_sock=accept(serv_sock, (struct sockaddr*)&clnt_adr,&clnt_adr_sz);
pthread_mutex_lock(&mutx);
clnt_socks[clnt_cnt++]=clnt_sock;
pthread_mutex_unlock(&mutx);
pthread_create(&t_id, NULL, handle_clnt, (void*)&clnt_sock);
pthread_detach(t_id);
printf("Connected client IP: %s \n", inet_ntoa(clnt_adr.sin_addr));
}
close(serv_sock);
return 0;
}
void * handle_clnt(void * arg)
{
int clnt_sock=*((int*)arg);
int str_len=0, i;
char msg[BUF_SIZE];
while((str_len=read(clnt_sock, msg, sizeof(msg)))!=0)
send_msg(msg, str_len);
pthread_mutex_lock(&mutx);
for(i=0; i<clnt_cnt; i++) // remove disconnected client
{
if(clnt_sock==clnt_socks[i])
{
while(i++<clnt_cnt-1)
clnt_socks[i]=clnt_socks[i+1];
break;
}
}
clnt_cnt--;
pthread_mutex_unlock(&mutx);
close(clnt_sock);
return NULL;
}
void send_msg(char * msg, int len) // send to all
{
int i;
pthread_mutex_lock(&mutx);
for(i=0; i<clnt_cnt; i++)
write(clnt_socks[i], msg, len);
pthread_mutex_unlock(&mutx);
}
void error_handling(char * msg)
{
fputs(msg, stderr);
fputc('\n', stderr);
exit(1);
}
코드를 대략적으로 분석하면 다음과 같다.
clnt_socks[clnt_cnt++]=clnt_sock;
새로운 연결이 형성될 때마다 변수 clnt_cnt와 배열 clnt_socks에 해당 정보를 등록한다.
pthread_create(&t_id, NULL, handle_clnt, (void*)&clnt_sock);추가된 클라이언트에게 서비스를 제공하기위한 쓰레드를 생성하고있다.
그리고 이 쓰레드에 의해 handle_clnt 함수가 실행된다.
pthread_detach(t_id);pthread_detach 함수 호출을 통해 종료된 쓰레드가 메모리에서 완전히 소멸되도록 하고 있다.
void send_msg(char * msg, int len)모든 클라이언트에게 메세지를 전송하는 기능을 제공하는 함수이다.
위 예제를 통해 넘어가야할 것은 채팅 서버의 구현 방식이아닌, 임계 영역의 구성형태이다.
위 예제는 임계영역과 관련해서 다음의 특징을 보인다.
"전역변수 clnt_cnt와 배열 clnt_socks에 접근하는 코드는 하나의 임계영역을 구성한다."
클라이언트가 새로 추가 및 삭제되면 변수 clnt_cnt와 배열 clnt_socks에는 동시에 변화가 생긴다. 때문에 다음과 같은 상황은 모두 데이터의 불일치를 유도해서 심각한 오류상황으로 이어질 수 있다.
- A 쓰레드는 배열 clnt_socks에서 소켓 정보 삭제, 동시에 B 쓰레드는 변수 clnt_cnt 참조
- A 쓰레드는 변수 clnt_cnt 참조, 동시에 B 쓰레드는 배열 clnt_socks에 소켓 정보 추가
따라서 위 예제에서 보이듯이 변수 clnt_cnt, 그리고 배열 clnt_socks의 접근 관련 코드는 묶어서 하나의 임계영역으로 구성해야 한다. 방금 말했던 접근은 주로 값의 변경을 뜻하고, 보다 다양한 상황에서 문제가 발생할 수 있기 때문에 문제의 원인을 정확히 이해해야 한다는 글이 공감될 것이다.
이어서 채팅 클라이언트 코드는 작성해보자. 이 예제는 입출력의 처리를 분리시키기위해 쓰레드를 생성하였다.
//chat_clnt.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <pthread.h>
#define BUF_SIZE 100
#define NAME_SIZE 20
void * send_msg(void * arg);
void * recv_msg(void * arg);
void error_handling(char * msg);
char name[NAME_SIZE]="[DEFAULT]";
char msg[BUF_SIZE];
int main(int argc, char *argv[])
{
int sock;
struct sockaddr_in serv_addr;
pthread_t snd_thread, rcv_thread;
void * thread_return;
if(argc!=4) {
printf("Usage : %s <IP> <port> <name>\n", argv[0]);
exit(1);
}
sprintf(name, "[%s]", argv[3]);
sock=socket(PF_INET, SOCK_STREAM, 0);
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family=AF_INET;
serv_addr.sin_addr.s_addr=inet_addr(argv[1]);
serv_addr.sin_port=htons(atoi(argv[2]));
if(connect(sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr))==-1)
error_handling("connect() error");
pthread_create(&snd_thread, NULL, send_msg, (void*)&sock);
pthread_create(&rcv_thread, NULL, recv_msg, (void*)&sock);
pthread_join(snd_thread, &thread_return);
pthread_join(rcv_thread, &thread_return);
close(sock);
return 0;
}
void * send_msg(void * arg) // send thread main
{
int sock=*((int*)arg);
char name_msg[NAME_SIZE+BUF_SIZE];
while(1)
{
fgets(msg, BUF_SIZE, stdin);
if(!strcmp(msg,"q\n")||!strcmp(msg,"Q\n"))
{
close(sock);
exit(0);
}
sprintf(name_msg,"%s %s", name, msg);
write(sock, name_msg, strlen(name_msg));
}
return NULL;
}
void * recv_msg(void * arg) // read thread main
{
int sock=*((int*)arg);
char name_msg[NAME_SIZE+BUF_SIZE];
int str_len;
while(1)
{
str_len=read(sock, name_msg, NAME_SIZE+BUF_SIZE-1);
if(str_len==-1)
return (void*)-1;
name_msg[str_len]=0;
fputs(name_msg, stdout);
}
return NULL;
}
void error_handling(char *msg)
{
fputs(msg, stderr);
fputc('\n', stderr);
exit(1);
}
'개발자과정준비 > TCP IP Socket Programming' 카테고리의 다른 글
| [Socket 프로그래밍] 18. 멀티쓰레드 기반의 서버구현 - 1 (1) | 2021.06.30 |
|---|---|
| [Socket 프로그래밍] 12. IO 멀티플렉싱(Multiplexing) (0) | 2021.06.29 |
| [Socket 프로그래밍] 11. 프로세스간 통신 (0) | 2021.06.28 |
| [Socket 프로그래밍] 10. 멀티프로세스 기반의 서버 구현 (0) | 2021.06.25 |
| [Socket 프로그래밍] 9. 소켓의 다양한 옵션 (0) | 2021.06.24 |
