TCP 기반 서버/클라이언트 1
TCP와 UDP에 대한 이해
인터넷 프로토콜 기반 소켓의 경우, 데이터 전송방법에 따라서 TCP 소켓과 UDP 소켓으로 나뉘고, 특히 TCP 소켓의 경우 연결을 지향하기 때문에 '스트림 기반 소켓' 이라고도 한다.
TCP(Transmission Control Protocol)는 '데이터 전송과정의 컨트롤'이라는 뜻을 갖고있다. 때문에 TCP 소켓의 정확한 이해를 위해서는 컨트롤의 방법과 범위에 대해 살펴봐야한다.
TCP/IP 프로토콜 스택
TCP를 이야기하기에 앞서 TCP에 속해있는 "TCP/IP 프로토콜 스택"을 먼저 설명하고자 한다. 다음 그림은 TCP/IP 프로토콜 스택(Stack, 계층)을 보여준다.

위 그림을 통해 TCP/IP 스택이 총 4개의 계층으로 나뉘어져있는 것을 알 수 있는데, 이는 데이터 송수신의 과정을 4개의 영역으로 계층화했다는 의미로 받아들일 수 있다.
즉 '인터넷 기반의 효율적인 데이터 전송'이라는 커다란 하나의 문제를 하나의 덩치 큰 프로토콜 설계로 해결한 것이 아니라, 그 문제를 작게 나눠서 계층화하여 탄생한 것이 'TCP/IP 프로토콜 스택' 인 것이다.
따라서 우리가 TCP 소켓을 생성해서 데이터를 송수신할 경우에는 다음 네 계층의 도움을 통해 데이터를 송수신하게 된다.
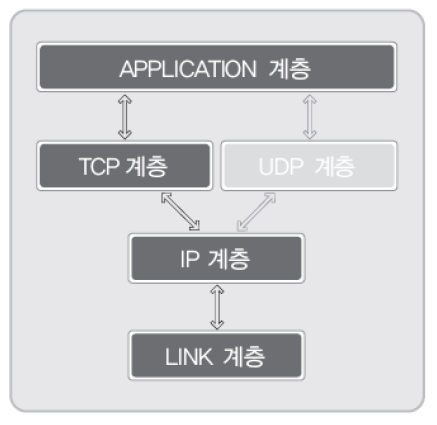
반면에 UDP 소켓을 생성해서 데이터를 송수신할 경우에는 다음 4계층의 도움을 통해 데이터를 송수신하게 된다.
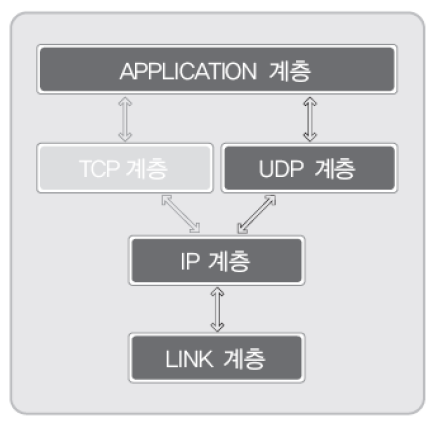
그리고 각각의 계층을 담당하는 것은 운영체제와 같은 소프트웨어이기도하고, NIC와같은 물리적인 장치이기도 하다.
OSI Layer(7계층)
데이터 통신에 사용되는 프로토콜 스택은 7계층으로 세분화된다. 그러나 앞서보인 그림에서와 같이 4계층으로 구분 짓기도 한다. 지금 우리 관점에서는 4계층으로 이해하고 있어도 충분하다.
그럼 이제 TCP/IP 프로토콜 스택을 계층별로 하나씩 살펴보기로 하자.
LINK 계층
LINK 계층은 물리적인 영역의 표준화에 대한 결과이다. 이는 가장 기본이 되는 영역으로 LAN, WAN, MAN과 같은 네트워크 표준과 관련된 프로토콜을 정의하는 영역이다. 두 호스트가 인터넷을 통해 데이터를 주고받으려면 다음 그림과 같이 물리적인 연결이 존재해야한다. 바로 이 부분에 대한 표준을 LINK 계층에서 담당하고 있다.
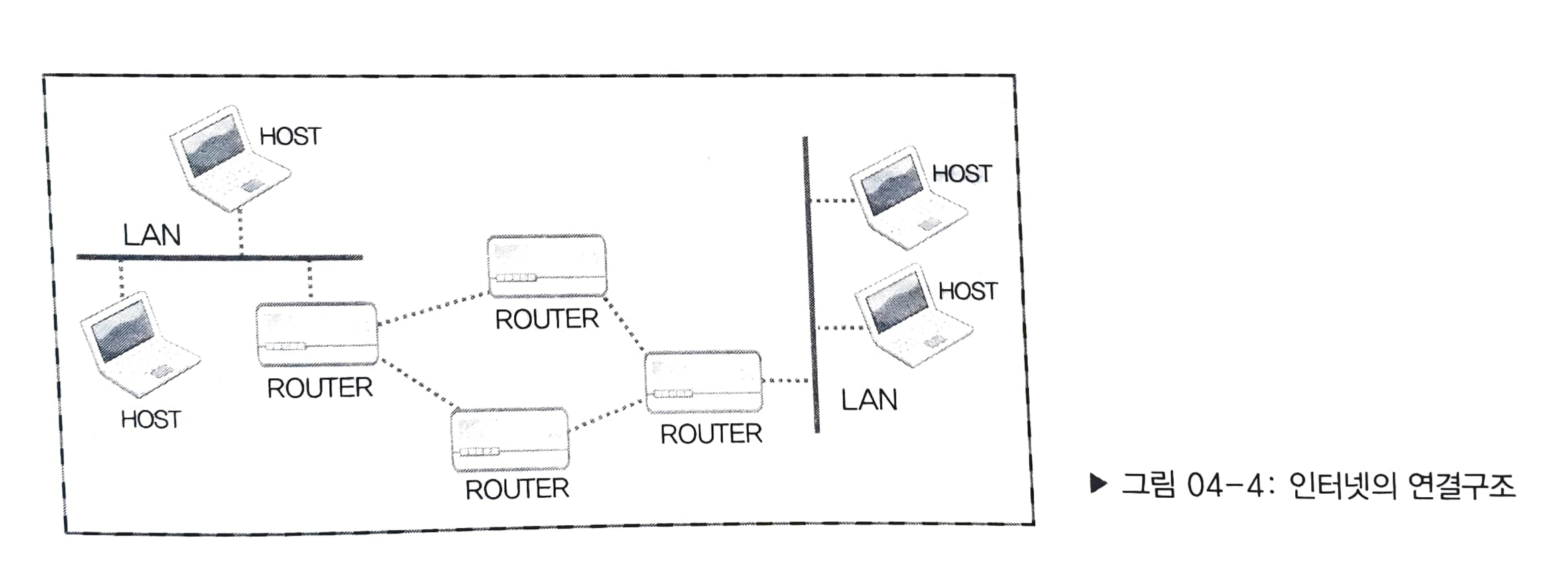
IP 계층
물리적인 연결이 형성되었을대, 데이터를 보낼 기본 준비가 됬다고 할 수 있다.
그런데 복잡하게 연결되어있는 인터넷을 통한 데이터의 전송을 위해 선행되어야 할 일은 경로의 선택이다.
목적지로 데이터를 전송하기위해 중간에 어떤 경로를 거쳐갈 것인가? 의 문제를 해결하는 것이 IP 계층이고, 이 계층에서 사용하는 프로토콜이 IP(Internet Protocol)이다.
IP 자체는 비연결지향적이며 신뢰할 수 없는 프로토콜이다. 데이터를 전송할대마다 거쳐야할 경로를 선택해주지만, 그 경로는 일정치 않다. 특히 데이터 전송 도중에 경로상에 문제가 발생하면 다른 경로를 선택해주는데, 이 과정에서 데이터가 손실되거나 오류가 발생하는 등의 문제가 발생한다고 해서 이를 해결해주지 않는다.
즉, 오류 발생에 대한 대비가 되어있지 않은 프로토콜이 IP이다.
TCP/UDP 계층
데이터 전송을 위한 경로의 검색을 IP계층에서 해결해주니, 그 경로를 기준으로 데이터를 전송만하면 된다.
TCP와 UDP 계층은 이렇듯 IP계층에서 알려준 경로정보를 바탕으로 데이터의 실제 송수신을 담당한다.
때문에 이 계층을 가리켜 '전송(Transport) 계층' 이라 한다.
전송계층에 존재하는 UDP는 TCP에 비해 상대적으로 간단하며, 이후에 별도로 언급하니 일단은 TCP에 대해서만 추가로 설명하도록 하겠다.
TCP는 신뢰성있는 데이터의 전송을 담당한다. 그런데 TCP가 데이터를 보낼때 기반이 되는 프로토콜이 IP(이것이 프로토콜이 스택의 구조로 계층화되어있는 이유이다)이다. 그럼 이 둘의 관계를 어떻게 이해하면 될까?
IP는 오로지 하나의 데이터 패킷(데이터 전송의 기본단위)이 전소오디는 과정에만 중심을 두고 설계되었다.
따라서 여러 개의 데이터 패킷을 전송한다 하더라도 각각의 패킷이 전송되는 과정은 IP에 의해 진행되므로 전송의 순서는 물론이거니와 전송 그 자체를 신뢰할 수 없다. 만약 IP만을 이용해서 데이터를 전송한다면 먼저 전송한 A 패킷보다 뒤에 전송한 B 패킷이 먼저 도달할 수도 있다. 그리고 이어서 전송한 A, B, C 패킷 중에서 A와 C 패킷만 전송될 수 있으며, 그나마 C 패킷은 손상된 상태로 전송될 수도 있다.
반면에 TCP 프로토콜이 추가되어 데이터를 송수신하면 데이터를 주고받는 과정에서 서로 데이터를 주고 받음을 확인한다. 그리고 분실된 데이터에 대해 재전송해주기때문에 데이터의 전송을 신뢰한다고 할 수 있다.
비록 IP가 데이터의 전송을 보장하지 않더라도 말이다.

위 그림은 TCP의 역할을 간단히 표현한 것이다.
결론적으로 말하면 IP의 상위계층에서 호스트 대 호스트의 데이터 송수신 방식을 약속하는 것이 TCP와 UDP이다.
TCP는 확인절차를 걸쳐서 신뢰성없는 IP에 신뢰성을 부여한 프로토콜이라 할 수 있다.
(사진이나 영상같이 큰거를 UDP로 사용하는데, 요즘 하드웨어가 많이 발전해서 거의 다 TCP로 사용함)
APPLICATION 계층
지금까지 설명한 내용은 소켓을 생성하면 데이터 송수신과정에서 자동으로 처리되는 것들이다. 데이터의 전송경로를 확인하는 과정이라든가 데이터 수신에대한 응답의 과정이 소켓이라는 것 하나에 감춰져 있기 때문이다.
그러나 감춰져있다는 표현보다는 이러한 일들에 대해 프로그래머를 자유롭게 해줬다는 표현이 더 정확할 것이다.
즉, 프로그래밍에 있어서 이러한 과정을 우리가 신경쓰지 않아도 된다는 뜻이다.
하지만 신경을 쓰지 않아도 될뿐이지, 몰라도 된다는 뜻은 아니다. 이러한 이론적인 내용들도 알고있어야 필요에 맞는 네트워크 프로그래밍을 작성할 수 있을 것이다.
최종적으로는 소켓이라는 도구가 우리에게 주어졌고, 우리는 이 도구를 이용해서 무엇인가를 만들면 된다.
이렇게 무엇인가를 만드는 과정에서 프로그램의 성격에 따라 클라이언트와 서버간의 데이터 송수신에 대한 약속(규칙)들이 정해지기 마련인데, 이를 가리켜 APPLICATION 프로토콜이라 한다.
그리고 대부분의 네트워크 프로그래밍은 APPLICATION 프로토콜의 설계 및 구현이 상당부분을 차지한다.
TCP 기반 서버, 클라이언트 구현
TCP 서버에서의 기본적인 함수 호출 순서
아래 그림은 TCP 서버 구현을 위한 기본적인 함수의 호출순서를 보이고 있다. 대부분의 TCP 서버 프로그램은 이 순서로 구현된다.

제일 먼저 socket() 함수의 호출을 통해 소켓을 생성한다. 그리고 주소 정보를 담기 위한 구조체 변수를 선언 및 초기화해서 bind 함수를 호출하여 소켓에 주소를 할당한다. 이 두 단계는 앞서했던 예제에 있었으니 그 이후의 과정에 대해 알아보자.
연결 요청 대기상태로의 진입
bind 함수 호출을 통해 소켓에 주소까지 할당했다면 이번에는 listen 함수 호출을 통해서 '연결요청 대기상태'로 들어갈 차례이다. 그리고 listen 함수가 호출되어야 클라이언트가 연결 요청을 할 수 있는 상태가 된다.
즉, listen함수가 호출되어야할 클라이언트는 연결요청을 위해 connect 함수를 호출할 수 있다.(이전에 connect 함수가 호출되면 오류 발생)
#include <sys/socket.h>
int listen(int sock, int backlog); // 성공 시 0, 실패시 -1 반환
// sock : 연결요청에 두고자하는 소켓의 디스크립터 전달
// 이 함수의 인자로 전달된 디스크립터의 소켓이 서버 소켓(리스닝 소켓)이 된다.
// backlog : 연결요청 대기 큐(Queue)의 크기정보 전달
// 5가 전달되면 큐의 크기가 5가되어 클라이언트의 연결요청을 5개까지 대기시킬 수 있다.
여기서 잠시 '연결요청 대기상태'의 의미와 '연결요청 대기 큐'라는 것에 대해서 별도로 알아보자.
서버가 '연결요청 대기상태'에 있다는 것은 클라이언트가 연결요청을 했을때 연결이 수락될때까지 연결요청 자체를 대기시킬 수 있는 상태에 있다는 것을 의미한다. 이를 그림으로 표현하면 다음과 같다.
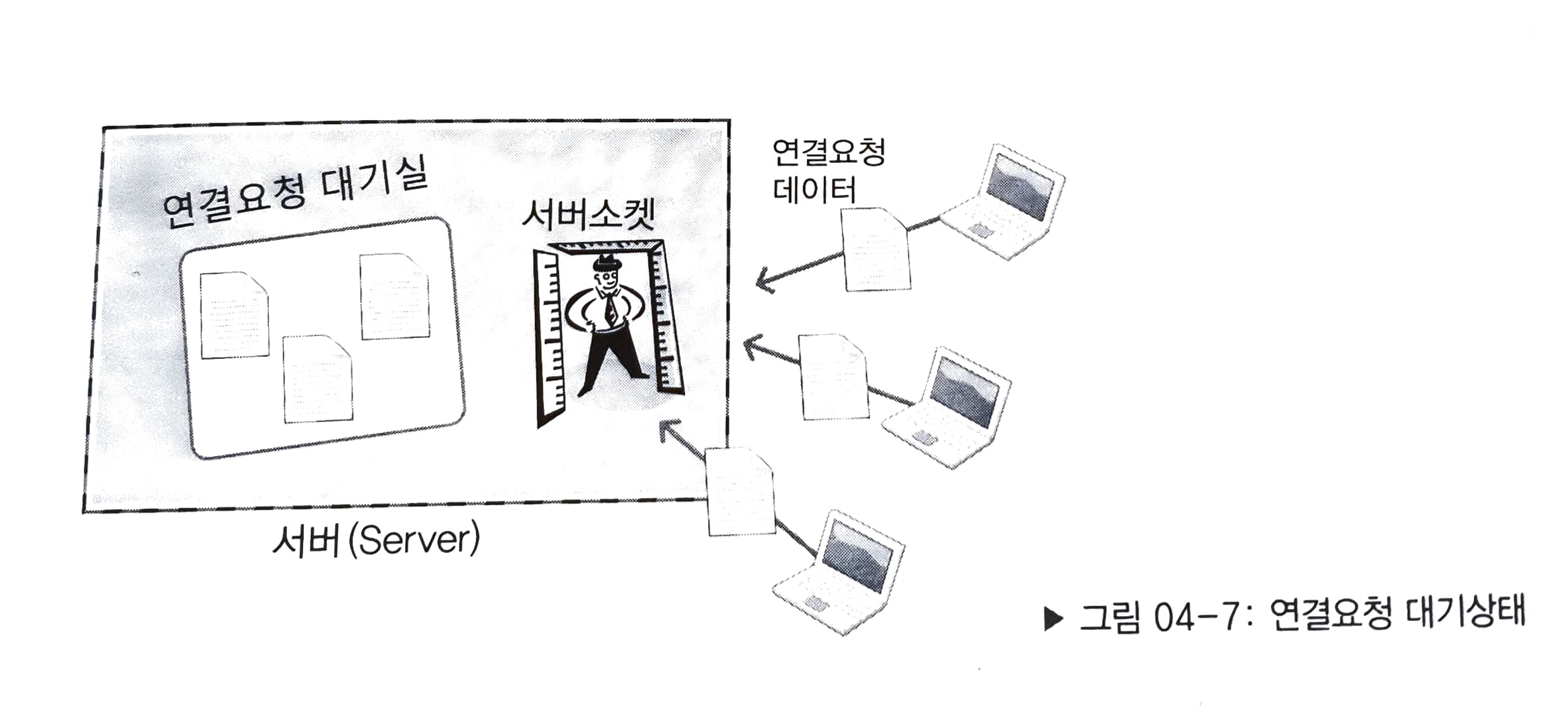
위 그림을 보면, listen 함수의 첫번째 인자로 전달된 파일 디스크립터의 소켓이 어떤 용도로 사용되는지 알 수 있다.
클라이언트의 연결요청도 인터넷을 통해서 흘러 들어오는 일종의 데이터 전송이기때문에, 이것을 받아들이려면 당연히 소켓이 하나 있어야 할 것이다. 서버 소켓의 역할이 바로 이것이다.
즉, 연결요청을 맞이하는, 일종의 문지기 또는 문의 역할을 한다고 볼 수 있다.
클라이언트가 연결될 수 있냐고 서버 소켓에게 물어보면, 서버 소켓은 친절한 문지기이기때문에 연결은 가능하지만, 지금 바쁘니 대기실에서 번호표를 뽑고 기다리라고 말하면서 대기실로 안내한다.
listen 함수가 호출되면, 이렇듯 문지기의 역할을 하는 서버 소켓이 만들어지고 listen 함수의 두번째 인자로 전달되는 정수의 크기에 해당하는 대기실이 만들어진다. 이 대기실을 가리켜 '연결요청 대기 큐'라 하며, 서버 소켓과 연결요청 대기 큐가 완전히 준비되어서 클라이언트의 연결요청을 받아 들일 수 있는 상태를 가리켜 '연결요청 대기상태'라 한다.
listen 함수의 두번째 인자로 전달될 적절한 인자의 값은 서버의 성격마다 다르지만, 웹 서버와 같이 잦은 연결요청을 받는 서버의 경우 최소 15 이상을 전달해야한다. 참고로 연결요청 대기 큐의 크기는 어디까지나 실험적 결과에 의존해서 결정하게 된다.
클라이언트의 연결요청 수락
listen 함수 호출 이후에 클라이언트의 연결요청이 들어왔다면, 들어온 순서대로 연결요청을 수락해야한다.
연결요청을 수락한다는 것은 클라이언트와 데이터를 주고받을 수 잇는 상태가 됨을 의미한다.
따라서 이러한 상태가 되기 위해 소켓이 필요하다.
데이터를 주고받으려면 소켓이 필요한데 서버 소켓을 사용해도 되냐고 되물을수도 있다.
그런데 서버 소켓은 문지기 역할이고, 클라이언트와 데이터 송수신을위해 서버 소켓을 사용하면 문지기가 없는 셈이된다. 때문에 소켓을 하나 더 만들어야 할것이다.
하지만 소켓을 직접 만들필요는 없다. 다음 함수의 호출 결과로 소켓이 만들어지고, 이 소켓은 연결요청을 한 클라이언트 소켓과 자동으로 연결된다.
#include <sys/socket.h>
int accept(int sock, struct sockaddr * addr, socklen_t * addrlen); // 성공 시 생성된 소켓의 파일 디스크립터, 실패시 -1 반환- sock : 서버 소켓의 파일 디스크립터 전달
- addr : 연결요청 한 클라이언트의 주소 정보를 담을 변수의 주소 값 전달. 함수 호출이 완료되면 인자로 전달된 주소의 변수에는 클라이언트의 주소 정보가 채워진다.
- addrlen : 두번째 매개변수 addr에 전달된 주소의 변수 크기를 바이트 단위로 전달. 단, 크기 정보를 변수에 저장한 다음에 변수의 주소 값을 전달한다. 함수 호출이 완료되면 크기정보로 채워져있던 변수에는 클라이언트의 주소 정보 길이가 바이트 단위로 계산되어 채워진다.
accept 함수는 '연결요청 대기 큐'에서 대기중인 클라이언트의 연결요청을 수락하는 기능의 함수이다.
따라서 accept 함수는 호출 성공 시 내부적으로 데이터 입출력에 사용할 소켓을 생성하고, 그 소켓의 파일 디스크립터를 반환한다. 중요한 점은 소켓이 자동으로 생성되어, 연결 요청을 한 클라이언트 소켓에 연결까지 이뤄주는 점이다.
다음 그림은 accept 함수 호출 시 일어나는 상황을 보이고 있다.

이렇듯 서버에서 별도로 생성한 소켓과 클라이언트 소켓이 직접 연결되는 것을 알아보았다.
이제 데이터를 주고받는 일만 살펴보면 된다.
Hello world 서버 프로그램 리뷰
이제 서버 프로그램의 구현 과정 전체에 대한 설명이 완료되었다. 따라서 저번 포스팅에서 알지 못했던 Hello World 서버 프로그램을 다시 한번 분석해보고자 한다.
// hello_server.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
void error_handling(char *message);
int main(int argc, char *argv[])
{
int serv_sock;
int clnt_sock;
struct sockaddr_in serv_addr;
struct sockaddr_in clnt_addr;
socklen_t clnt_addr_size;
char message[] = "Hello World!";
if(argc != 2)
{
printf("Usage : %s <port>\n", argv[0]);
exit(1);
}
serv_sock=socket(PF_INET, SOCK_STREAM, 0);
if(serv_sock == -1)
error_handling("Socket() error");
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family=AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port = htons(atoi(argv[1]));
if(bind(serv_sock, (struct sockaddr*) &serv_addr, sizeof(serv_addr)) == -1)
error_handling("bind() error");
if(listen(serv_sock, 5) == -1)
error_handling("listen() error");
clnt_addr_size = sizeof(clnt_addr);
clnt_sock = accept(serv_sock, (struct sockaddr*)&clnt_addr, &clnt_addr_size);
if(clnt_sock == -1)
error_handling("accept() error");
write(clnt_sock, message, sizeof(message));
close(clnt_sock);
close(serv_sock);
return 0;
}
void error_handling(char *message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
}천천히 중요한 구절만 곱씹어 보도록 하자.
serv_sock=socket(PF_INET, SOCK_STREAM, 0);서버 프로그램의 구현 과정에서 제일먼저 해야하는 소켓의 생성이다.
따라서 소켓을 생성하고있고, 이때 생성하는 소켓은 아직 서버 소켓이라 부르기 이른 상태이다.
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family=AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port = htons(atoi(argv[1]));소켓의 주소할당을 위해 구조체 변수를 초기화하고 bind 함수를 호출하고 있다.
if(listen(serv_sock, 5) == -1)연결요청 대기상태로 들어가기위해 listen 함수를 호출하고있다.
연결요청 대기 큐의 크기도 5로 설정하고있다. 이제 생성한 소켓이 서버소켓이라고 할 수 있다.
clnt_sock = accept(serv_sock, (struct sockaddr*)&clnt_addr, &clnt_addr_size);accept 함수가 호출되었으니, 대기 큐에서 첫번째로 대기 중에 있는 연결요청을 참조하여 클라이언트와의 연결을 구성하고, 이때 생서오딘 소켓의 파일 디스크립터를 반환한다.
참고로 이 함수가 호출되었을때 대기 큐가 비어있는 상태라면, 대기 큐가 찰때까지(클라이언트의 연결요청이 들어올때까지) accept 함수는 반환하지 않는다.
write(clnt_sock, message, sizeof(message));
close(clnt_sock);
close(serv_sock);write 함수 호출을 통해 클라이언트에게 데이터를 전송하고 있다. 그리고 close 함수 호출을 통해 연결을 끊고 있다.
저번 포스팅의 서버 프로그램 코드 예제가 서버 구현의 순서를 그대로 옮겨놓은 코드라고 할 수 있다.
이렇듯 서버 프로그램의 기본 구현과정은 간단하진 않지만 어느 정도 패턴이 있음을 알 수 있다.
TCP 클라이언트의 기본적인 함수 호출 순서
이번엔 클라이언트 구현순서에 대해 이야기해보자. 앞에서 언급했듯이 클라이언트의 구현과정은 서버에 비해 매우 간단하다. '소켓의 생성', 그리고 '연결의 요청'이 전부이기 때문이다.
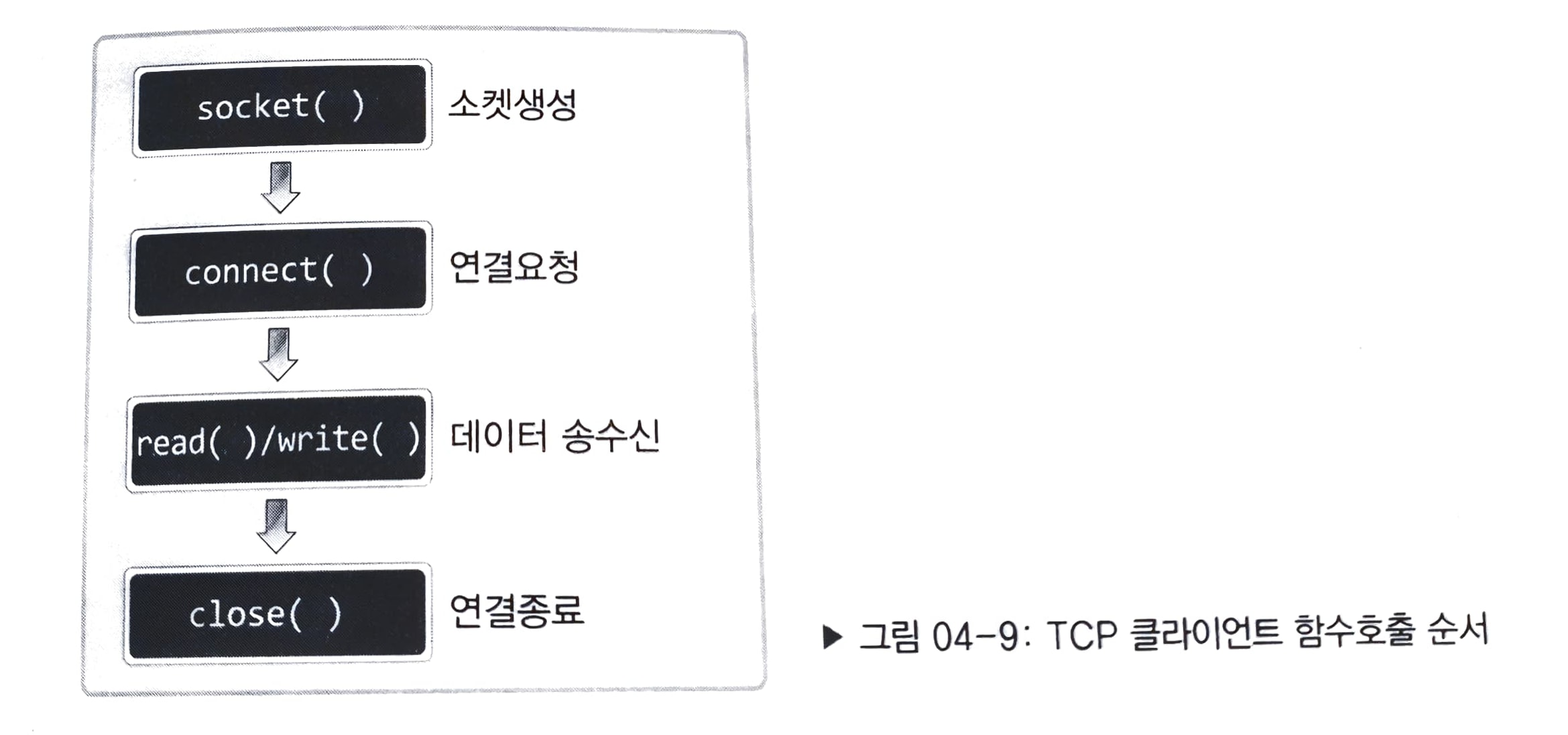
서버의 구현과정과 비교해서 차이가 있는 부분은 '연결요청'이라는 과정이다. 이는 클라이언트 소켓을 생성한 후에 서버로 연결을 요청하는 과정이다. 서버는 listen 함수를 호출한 이후부터 연결요청 대기 큐를 만들어 놓는다.
따라서 그 이후부터 클라이언트는 연결 요청을 할 수 있다.
#include <sys/socket.h>
int connect(int sock, struct sockaddr * servaddr, sokelen_t addrlen); // 성공 시 0, 실패 시 -1 반환
- sock : 클라이언트 소켓의 파일 디스크립터 전달
- servaddr : 연결요청 할 서버의 주소정보를 담은 변수의 주소 값 전달
- addrlen : 두번째 매개변수 servaddr에 전달된 주소의 변수 크기를 바이트 단위로 전달
클라이언트에 의해 connect 함수가 호출되면 다음 둘 중 한가지 상황이 되어야 함수가 반환된다.(함수 호출이 완료된다)
- 서버에 의해 연결요청이 접수되었다.
- 네트워크 단절 등 오류상황이 발생해서 연결요청이 중단되었다.
여기서 주의할 점은 위에서 말하는 '연결 요청의 접수'이다. 서버의 accept 함수 호출을 의미하는 것이 아니라는 점이다.
이는 클라이언트 연결요청 정보가 서버의 연결요청 대기 큐에 등록된 상황을 의미하는 것이다.
때문에 connect 함수가 반환했더라도 당장에 서비스가 이뤄지지 않을 수도 있음을 기억해야 한다.
클라이언트 소켓의 주소 정보는 어디?
서버를 구현하면서 반드시 거쳤던 과정 중 하나가 서버 소켓에 IP와 PORT를 할당하는 것이다.
그런데 생각해보면 클라이언트 프로그램의 구현순서에는 소켓의 주소할당 과정이 없었다. 그저 소켓을 생성하고 서버로의 연결을 위해서 connect 함수를 호출한 것이 전부였다.
그렇다면 클라이언트 소켓은 IP와 PORT가 할당이 불필요하다고 생각할 수 있다. 하지만 네트워크를 통해서 데이터를 송수신하려면 IP와 PORT가 반드시 할당되어야한다. 그렇다면 클라이언트 소켓은 언제, 어디서, 어떻게 할당이 가능했던 것일까?
- 언제 : connect 함수가 호출될 때
- 어디서 : 운영체제에서(정확히 표현하면 커널에서)
- 어떻게 : IP는 컴퓨터(호스트)에 할당된 IP로, PORT는 임의로 선택해서
즉 bind 함수를 통해 소켓에 IP와 PORT를 직접 할당하지 않아도 connect 함수호출 시 자동으로 소켓에 IP와 PORT를 직접 할당하지 않아도 connect 함수 호출 시 자동으로 소켓에 IP와 PORT가 할당된다.
따라서 클라이언트 프로그램을 구현할때는 bind 함수를 명시적으로 호출할 필요가 없다.
TCP 기반 서버, 클라이언트의 함수 호출 관계
지금까지 TCP 서버, TCP 클라이언트 프로그램의 구현순서를 알아봤는데 사실 이 둘은 서로 독립된 과정이 아니기 때문에 하나의 과정으로 머리속에 그릴 수 있어야한다. 그래서 이 두 과정을 하나의 그림을 정리해보고자 한다.

전체적인 흐름을 보자면, 서버는 소켓 생성 이후에 bind, listen 함수의 연이은 호출을 통해 대기상태에 들어가고, 클라이언트는 connect 함수 호출을 통해 연결요청을 하게 된다. 특히 클라이언트 서버는 서버 소켓의 listen 함수 호출 이후에 connect 함수를 호출하기에 앞서 서버가 accept 함수를 먼저 호출할 수 있다는 사실도 함께 기억하도록 하자.
물론 이때는 클라이언트가 connect 함수를 호출할 때까지 서버는 accept 함수가 호출된 위치에서 블로킹 상태에 놓이게 된다.
Iterative 기반의 서버, 클라이언트 구현
에코 서버와 에코 클라이언트를 구현해보자.
에코 서버는 클라이언트가 전송하는 문자열 데이터를 그대로 재전송하는(문자열 데이터를 에코(echo)시키는) 서버이다.
그런데 구현에 앞서 Iterative 서버의 구현에 대해 알아야한다.
Iterative 서버의 구현
예제로 구현했던 Hello World 서버는 한 클라이언트의 요청에만 응답을 하고 바로 종료되버렸다. 때문에 방금까지 언급했던 연결 요청 대기 큐의 크기도 의미가 없어졌다. 그런데 이는 우리가 생각하는 서버의 모습이 아니다.
코드에서 큐의 크기까지 설정해놨다면 연결요청을 하는 모든 클라이언트에게 약속되어 있는 서비르르 제공해야한다.
그렇다면 계속 들어오는 클라이언트 연결요청을 수락하기 위해서는 서버의 코드 구현을 확장해야한다.
이를 위해 accept 함수를 반복호출하면된다.

그림의 흐름도를 대략 본다면 accept 함수가 호출된 다음에 입출력 함수인 read, write 함수를 호출하고 있다.
그리고 이어서 close 함수를 호출하고 있는데, 이는 서버 소켓을 대상으로 하는 것이 아니라 accept 함수의 호출과정에서 생성된 소켓을 대상으로 하는 것이다.
close 함수까지 호출되었다면 한 클라이언트에 대한 서비스가 완료된 것이다. 그럼 이어서 클라이언트에게 서비스하기위해서는 또다시 accept 함수를 호출해야 한다.
하지만 서버인데 한 순간에 하나의 클라이언트에게만 서비스를 제공하는데, 이는 프로세스와 쓰레드를 알고나면 동시에 둘 이상의 클라이언트에게 서비르르 제공하는 서버를 만들 수 있게 된다. 그러니 지금은 여기까지만 코드를 작성해보자.
Iterative 에코 서버, 에코 클라이언트
앞서 설명한 형태의 서버를 가리켜 Iterative 서버라 한다. 이번에는 Iterative 형태로 동작하는 에코 서버, 에코 클라이언트 코드를 작성해보자.
먼저 프로그램의 기본 동작방식을 정리하자면 다음과 같다.
- 서버는 한 순간에 하나의 클라이언트와 연결되어 에코 서비스를 제공한다.
- 서버는 총 다섯 개의 클라이언트에게 순차적으로 서비를 제공하고 종료한다.
- 클라이언트는 프로그램 사용자로부터 문자열 데이터를 입력받아서 서버에 전송한다.
- 서버는 전송 받은 문자열 데이터를 클라이언트에게 재전송한다. 즉, 에코 시킨다.
- 서버와 클라이언트간의 문자열 에코는 클라이언트가 Q를 입력할때까지 계속한다.
이 요구사항에 맞춰서 동작하는 에코 서버 코드를 작성해보자. 특히 accept 함수의 반복 호출이 어떻게 이뤄지는지 주목해보자.
// echo.server.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#define BUF_SIZE 1024
void error_handling(char *message);
int main(int argc, char *argv[])
{
int serv_sock, clnt_sock;
char message[BUF_SIZE];
int str_len, i;
struct sockaddr_in serv_adr, clnt_adr;
socklen_t clnt_adr_sz;
if(argc != 2)
{
printf("Usage : %s <port>\n", argv[0]);
exit(1);
}
serv_sock = socket(PF_INET, SOCK_STREAM, 0);
if(serv_sock == -1)
error_handling("socket() error");
memset(&serv_adr, 0, sizeof(serv_adr));
serv_adr.sin_family = AF_INET;
serv_adr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_adr.sin_port = htons(atoi(argv[1]));
if(bind(serv_sock, (struct sockaddr*)&serv_adr, sizeof(serv_adr)) == -1)
error_handling("bind() error");
if(listen(serv_sock, 5) == -1)
error_handling("listen() error");
clnt_adr_sz = sizeof(clnt_adr);
for(i = 0; i < 5; i++)
{
clnt_sock = accept(serv_sock, (struct sockaddr*)&clnt_adr, &clnt_adr_sz);
if(clnt_sock == -1)
error_handling("accept() error");
else
printf("Connected client %d \n", i + 1);
while((str_len = read(clnt_sock, message, BUF_SIZE)) != 0)
write(clnt_sock, message, str_len);
close(clnt_sock);
}
close(serv_sock);
return 0;
}
void error_handling(char *message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
}
이어서 에코 클라이언트 코드를 작성해보자.
// echo_client.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#define BUF_SIZE 1024
void error_handling(char *message);
int main(int argc, char *argv[])
{
int sock;
char message[BUF_SIZE];
int str_len;
struct sockaddr_in serv_adr;
if(argc != 3)
{
printf("Usage : %s <IP> <port> \n", argv[0]);
exit(1);
}
sock = socket(PF_INET, SOCK_STREAM, 0);
if(sock == -1)
error_handling("socket() error");
memset(&serv_adr, 0, sizeof(serv_adr));
serv_adr.sin_family = AF_INET;
serv_adr.sin_addr.s_addr = inet_addr(argv[1]);
serv_adr.sin_port = htons(atoi(argv[2]));
if(connect(sock, (struct sockaddr*)&serv_adr, sizeof(serv_adr)) == -1)
error_handling("connect() error!");
else
puts("Connect........");
while(1)
{
fputs("Input message(Q to quit) : ", stdout);
fgets(message, BUF_SIZE, stdin);
if(!strcmp(message, "q\n") || !strcmp(message, "Q\n"))
break;
write(sock, message, strlen(message));
str_len = read(sock, message, BUF_SIZE - 1);
message[str_len] = 0;
printf("Message form server : %s", message);
}
close(sock);
return 0;
}
void error_handling(char *message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
}
서버 코드를 실행하고, 클라이언트 코드를 실행해보자.
그렇게되면 문자열을 입력할 수 있게되는데, 문자열을 입력하면 서버에서 그 문자열을 출력한다.(Q를 입력하면 종료된다)

이때 Hello World때 처럼 서버가 종료되지 않고 계속 유지되는 것을 확인할 수 있다.
echo 서버는 클라이언트가 호출될때마다 count가 ++되어서 출력되는 것을 확인할 수 있을 것이다.

에코 클라이언트의 문제점?
다음은 echo_client.c의 삽입된 입출력 문장이다.
write(sock, message, strlen(message));
str_len = read(sock, message, BUF_SIZE - 1);
message[str_len] = 0;
printf("Message form server : %s", message);위의 코드는 "read, write 함수가 호출될 때마다 문자열 단위로 실제 입출력이 이뤄진다" 라는 잘못된 가정이 존재한다.
write 함수를 호출할 때마다 하나의 문장을 전송하니 이렇게 가정하는 것도 무리는 아니다.
하지만 TCP는 데이터의 경계가 존재하지 않고, 위에서 구현한 클라이언트는 TCP 클라이언트이기 때문에 둘 이상의 write 함수 호출로 전달된 문자열 정보가 묶여서 한번에 서버로 전송될 수 있다. 그리고 그러한 상황이 발생하면 클라이언트는 한번에 둘 이상의 문자열 정보를 서버로부터 되돌려 받아서 원하는 결과를 얻지 못할 수도 있다.
그리고 서버가 다음과 같이 판단하는 상황도 생각해봐야한다.
"문자열의 길이가 기니까 문자열을 두 개의 패킷에 나눠보낸다"
서버는 한번의 write 함수호출로 데이터 전송을 명령했지만, 전송할 데이터의 크기가 크다면 운영체제는 내부적으로 이를 여러 조각으로 나눠서 클라이언트에게 전송할 수도 있다. 그리고 이 과정에서 데이터의 모든 조각이 클라이언트에게 전송되지 않았음에도 불구하고, 클라이언트는 read 함수를 호출할지도 모른다.
이 모든 문제는 TCP의 데이터 전송 특성에서 비롯된 것이다. 이 문제 해결법은 다음에 차차 알아가도록하고 지금 구현한 에코 서버와 에코 클라이언트는 운이 좋게 별 무리없이 제대로 된 서비스의 결과를 보이고있다.
이는 송수신하는 데이터의 크기가 작고, 실제 실행환경이 하나의 컴퓨터 또는 근거리에 놓여있는 두 개의 컴퓨터이다 보니 오류가 발생하지 않았을뿐, 오류 발생확률은 여전히 존재한다고 볼 수 있다.
'개발자과정준비 > TCP IP Socket Programming' 카테고리의 다른 글
| [Socket 프로그래밍] 6. UDP 기반 서버/클라이언트 (0) | 2021.06.21 |
|---|---|
| [Socket 프로그래밍] 5. TCP 기반 서버/클라이언트 2 (1) | 2021.06.18 |
| [Socket 프로그래밍] 3. 주소체계와 데이터 정렬 (0) | 2021.06.16 |
| [Socket 프로그래밍] 2. 소켓의 타입과 프로토콜의 설정 (0) | 2021.06.15 |
| [Socket 프로그래밍] 1. 네트워크 프로그래밍과 소켓의 이해 (0) | 2021.06.14 |
