System.Text.StringBuilder
string을 다루면 반드시 함께 설명되는 클래스가 StringBuilder이다. string 타입은 불변 객체(immutable object)이기 때문에 string에 대한 모든 변환은 새로운 메모리 할당을 발생시킨다. 예를들어 string ToLower 메서드를 보자.
string txt = "Hello World";
string lwrText = txt.ToLower();
txt 변수는 Heap에 있는 "Hello World"를 가리킨다. 그 상태에서 ToLower 메서드를 호출하면 txt 변수에 담긴 문자열이 소문자로 변경되는 것이 아니라 원문이 통째로 복사된 다음 그것이 소문자로 변경되어 반환되는 절차를 거친다.

불변 타입의 string 클래스가 발생시키는 가장 큰 문제는 문자열을 더할 대다. 예를 들어, 다음 코드를 실행해보자.
string txt = "Hello World";
for(int i = 0; i < 300000; i++)
{
txt = txt + "1";
}필자는 이 코드를 실행하는데 약 27초가 걸렸다. 왜 이렇게 오래 걸렸는지 내부 동작을 살펴보면 쉽게 이해할 수 있다.
1. Heap 영역에 "Hello World" 문자열을 담은 공간을 할당한다.
2. 스택에 있는 txt 변수에 1번 과정에서 할당된 Heap의 주소를 저장한다.
3. txt + "1" 동작을 수행하기 위해 txt.Length + "1".Length에 해당하는 크기의 메모리를 힙에 할당한다. 그 메모리에 txt 변수가 기리키는 힙의 문자열과 "1" 문자열을 복사한다.
4. 다시 스택에 있는 txt 변수에 3번 과정에서 새롭게 할당된 힙의 주소를 저장한다.
5. 3번과 5번의 과정을 30만 번 반복한다.
문제는 3번 과정에 있다. 끊임없이 메모리를 할당하고 이전의 문자열을 다시 복사하는 과정을 거치기 때문에 실행 시간이 27초나 걸린 것이다.
바로 이런 문제를 해결하기 위해 BCL(Basc Class Library)에 추가된 클래스가 StringBuilder다. StringBuilder는 Append 메서드를 제공하는데 밑의 예제를 StringBuilder를 이용해 개선하면 다음과 같다.
string txt = "Hello World";
StringBuilder sb = new StringBuilder();
sb.Append(txt);
for(int i = 0; i<300000; i++)
{
sb.Append("1");
}
string newText = sb.ToString();
이 코드를 실행하는 데는 3ms가 채 걸리지 않는다. 위위 예제의 실행에 27초씩이나 걸린 것과 비교하면 획기적인 성능 향상이라고 볼 수 있다. 이번에도 내부 연산 과정을 보면 그 이유를 알 수 있다.
1. StringBuilder는 내부적으로 일정한 양의 메모리를 미리 할당한다.
2. Append 메서드에 들어온 인자를 미리 할당한 메모리에 복사한다.
3. 2번 과정을 30만번 반복한다. Append로 추가된 문자열이 미리 할당한 메모리보다 많아지면 새롭게 여유분의 메모리를 할당한다.
4. ToString 메서드를 호출하면 연속적으로 연결된 하나의 문자열을 반환한다.
즉, 잦은 메모리 할당과 복사가 없어졌기 때문에 그만큼 성능이 향상된 것이다. 이 때문에 문자열을 연결하는 작업이 많을 때는 반드시 StringBuilder를 사용하는 것을 권장한다고 한다.
System.Text.Encoding
'A', 'B', 'C'라는 문자는 시스템에 내장된 폰트를 기반으로 출력된 일종의 "그림"에 불과하다. 내부적으로 이런 문자는 숫자(010101같은)에 대응된다. 이처럼 문자가 숫자로 표현되는 것을 인코딩(encoding: 부호화)라고 한다.
만약 약속을 했다고 해보자. 'A',는 1, 'B'는 2, 'C'는 3, ... 과 같은 식으로 영문자를 숫자 코드로 대응시키는 것이다. 이렇게 대응된 방식에 이름을 붙여 "AJ"코드라고 하자. 그런데 누군가는 또다른 방식의 숫자코드를 사용할 수 있다. 'A'는 65, 'B'는 66, 'C'는 67, ... 이 될 수 있다. 실제로 미국에서는 이런 식으로 숫자 코드를 대응시켜 ASCII라는 표준을 마련했다.
이렇게 문자 데이터 자체는 그대로지만 그것을 어떤 코드에 대응시키느냐에 따라 'A' 문자가 1이 될 수도 있고, 65가 될수도 있다. 예를 들어 "AJ 코드"를 따르는 'A' 문자를 "ASCII 코드"로 변환하려면 코드값을 1에서 65로 바꿔줘야하는 것이다.
"AJ 코드"는 설명을 위해 이 글에서 임의로 만들어 낸 것에 불과하지만 사실상 코드 체계는 필요에 의해 만들면 되기 때문에 현재 다양한 인코딩 방식이 산재한다. 우선 초기의 ASCII 코드는 7비트(0~127)만 사용했기 때문에 알파벳 대소문자, 숫자, 일부 통신용 제어 코드를 포함하는 수준에서 결정됐다. 물론 7비트의 ASCII 코드로는 한글, 한자, 일본어 등의 언어를 표현할 수 없었기 때문에 전 세계에서 자국의 언어를 표현하기 위해 코드를 확장하기 시작했다. 한글도 이 과정에서 EUC-KR, CP949, KS_C_5601_1987 등의 다양한 인코딩 방식이 나온다.
시간이 지나면서 유니코드라는 산업 표준이 나오긴 했지만 이것마저도 부호화를 어떻게 하느냐에 따라 UTF-7, UTF-8, UTF-16, UTF-32로 나뉘게 된다. 이렇게 복잡해진 코드 체계를 쉽게 사용할 수 있도록 BCL에서는 Encoding 타입을 제공한다. 다음은 Encoding 타입의 대표적인 정적 속성을 보여준다.

System.Text.Regular.Expressions.Regex
정규 표현식(regular expression)은 문자열 처리에 대한 일반적인 규칙을 표현하는 형식 언어다. 즉, 그 자체가 하나의 언어로서 다뤄질 수 있는데, 지면상 모든 내용을 다루기는 어렵고, C#에서 간단하게 정규 표현식을 사용하는 방법을 살펴보자.
웹 사이트에 회원가입을 하다 보면 전자 메일 주소를 입력하곤 한다. 그런 경우 입력된 문자열이 전자 메일 형식에 어긋나면 정상적인 메일 주소를 입력하라는 메시지 창이 뜨는데, 이 기능은 어떻게 구현 된 것일까? 이를 위해 우선 허용되는 전자 메일의 규칙을 정리해야 한다.
- 반드시 '@'문자를 한번 포함해야 한다.
- @ 문자 이전의 문자열에는 문자와 숫자만 허용된다(특수문자를 포함해서는 안된다)
- @ 문자 이후의 문자열에는 문자와 숫자만 허용되지만 반드시 하나 이상의 점(Dot)을 포함해야 한다.
이런 규칙에 따라 코드를 만들면 다음과 같다.
using System;
class Program
{
static void Main(string[] args)
{
string email = "tester@test.com";
Console.WriteLine(IsEmail(email));
}
private static bool IsEmail(string email)
{
string[] parts = email.Split('@');
if(parts.Length != 2)
{
return false;
}
if(IsAlphaNumeric(parts[0]) == false)
{
return false;
}
parts = parts[1].Split('.');
if(parts.Length == 1)
{
return false;
}
foreach (var part in parts)
{
if(IsAlphaNumeric(part) == false)
{
return false;
}
}
return true;
}
static bool IsAlphaNumeric(string text)
{
foreach (var ch in text)
{
if(char.IsLetterOrDigit(ch) == false)
{
return false;
}
}
return true;
}
}
비교를 위해 이와 동일한 기능을 정규 표현식으로 구현해 보자. 전자 메일 형식을 만족하는 정규 표현 식은 다음과 같다.
^([0-9a-zA-Z]+)@([0-9a-zA-Z]+)( \.[0-9a-zA-Z]+){1,}$
- ^ : 문장의 시작이 다음 규칙을 만족해야함.
- ([0-9a-zA-Z]+) : 영숫자가 1개 이상
- @ : 반드시 '@' 문자가 있음
- ([0-9a-zA-Z]+) : 영숫자가 1개 이상
- ( \.[0-9a-zA-Z]+) : 점(.)과 1개 이상의 영숫자
- {1,} : 이전의 규칙이 1번 이상 반복(즉, 점과 1개 이상의 영숫자가 반복)
- $ : 이전의 규칙을 만족하면서 끝남(즉, 점과 1개 이상의 영숫자가 1번 이상 반복되면서 끝남)
정규 표현식에 해당하는 문자열을 뽑아내기 위한 준비 학습이 필요하긴 하지만 일단 이렇게 추출된 문자열로 코드를 만들면 위의 예제 코드에 비해 확실히 간결하게 문제를 해결할 수 있다.
class Program
{
static void Main(string[] args)
{
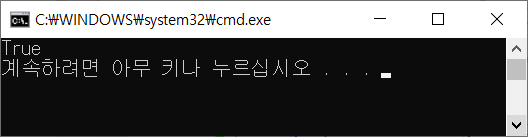
string email = "tester@test.com";
Console.WriteLine(IsEmail2(email));
}
private static bool IsEmail2(string email)
{
Regex regex =
new Regex(@"^([0-9a-zA-Z]+)@([0-9a-zA-Z]+)(\.[0-9a-zA-Z]+){1,}$");
return regex.IsMatch(email);
}
}
Regex 타입에는 패턴 일치를 판단하는 IsMatch 메서드뿐 아니라 패턴과 일치하는 문장을 다른 문장으로 치환하는 Replace 메서드도 제공된다.
Replace 기능은 string 타입에서도 제공되지만 아쉽게도 대소문자가 구분되어 동작한다. 즉, string, Replace("World", "Universe"); 코드는 대소문자가 다른 "world" 단어는 치환하지 못한다. 물로느 대소문자를 구분하지 않는 Replace 메서드를 직접 새롭게 만들어도 되지만 정규 표현식을 이용하는 편이 더 쉬울 수 있다.
using System;
using System.Text.RegularExpressions;
class Program
{
static void Main(string[] args)
{
string txt = "Hello, World! Welcome to my world!";
Regex regex = new Regex("world", RegexOptions.IgnoreCase);
string result = regex.Replace(txt, funcMatch);
Console.WriteLine(result);
}
private static string funcMatch(Match match)
{
return "Universe";
}
}
Regex 타입의 Replace 메서드는 생성자에서 미리 입력받은 패턴을 첫 번째 인자로 전달된 문자열에서 찾는다. 위의 예제에서는 "Hello, World! Welcome to my world!" 문장에서 대소문자 구분 없이 "world"단어를 찾는 것이다. 패턴에 부합하는 문자열을 찾으면 Replace 메서드는 두 번째 인자로 전달된 델리게이트 메서드를 호출해서 결과를 알린다. Replace 메서드는 치환 기능을 하기 때문에 델리게이트 메서드가 반환하는 문자열로 패턴에 해당하는 문자열을 교체한다. 따라서 위의 코드에서는 funcMatch 메서드에서 대소문자 구분 없이 "world" 단어가 검색될 대마다 "Universe" 문자열을 반환하기 때문에 결국 "Hello, World! Welcome to my Universe"로 바뀌는 것이다.
'개발자과정준비 > C#' 카테고리의 다른 글
| [C#] 비동기 호출 (0) | 2021.11.02 |
|---|---|
| [C#] 스레딩(threading) (0) | 2021.10.21 |
| [C#] 문자열(String) 처리 - 1 (0) | 2020.09.26 |
| [C#] 시간(DateTime, TimeSpan, Diagnostics.Stopwatch) (0) | 2020.09.19 |
| [C#] LiNQ (0) | 2020.08.29 |
